No babysitting, not today

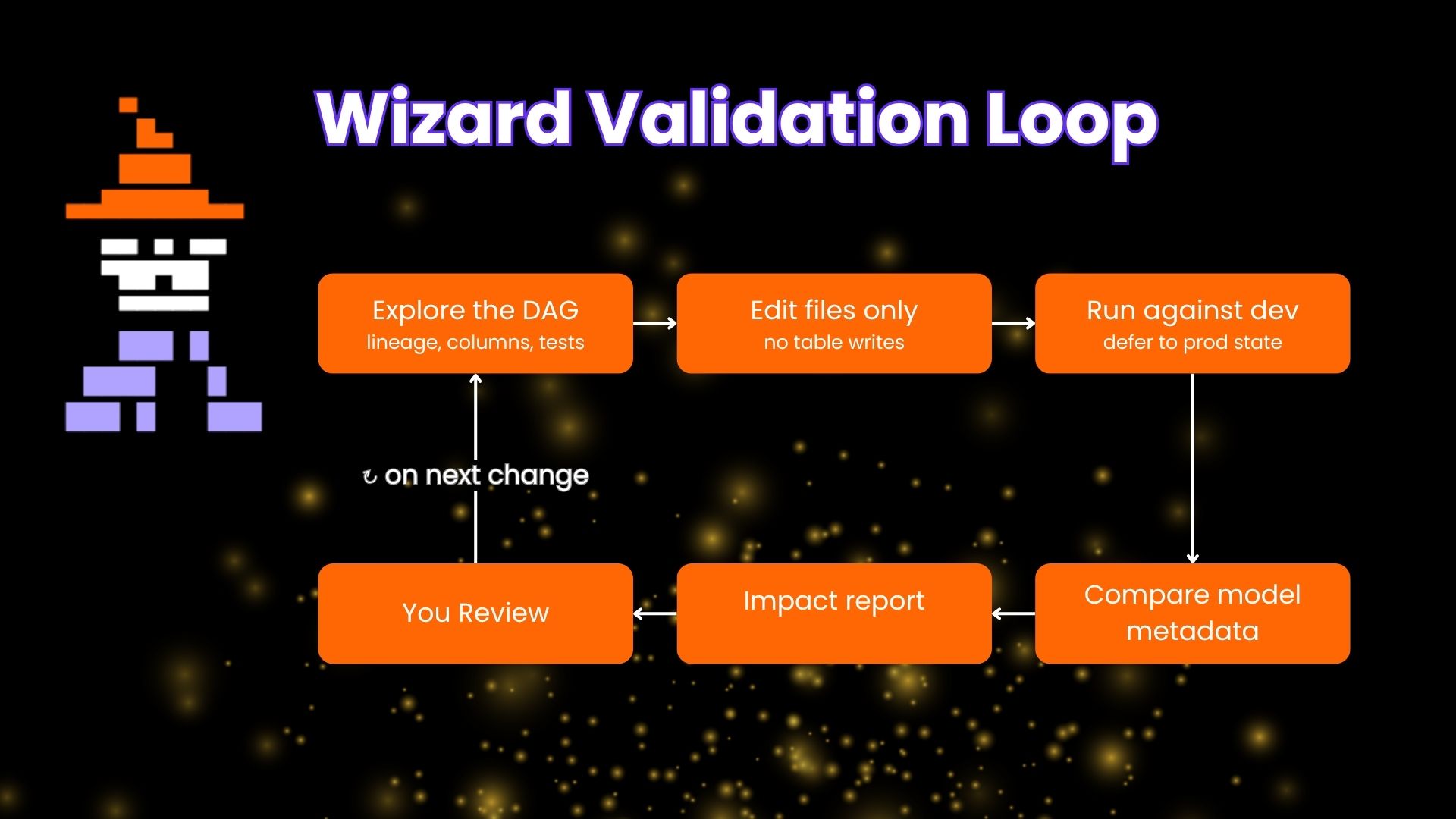
We recently released dbt Wizard, a CLI for doing agentic data work on dbt. This is a harness specifically built for data work and as such I was excited to spend an afternoon running dbt Wizard across a personal project with about 100 models or so that I've been maintaining for a while. You can use this project to see firsthand some of the differentiators for Wizard, particularly how the validation loop works.
Data projects are never done and I had a few tasks I've been putting off:
- Migrating from MotherDuck to Iceberg + BigQuery
- Upgrading dbt Core to dbt Fusion
- Migrating from dbt Core to dbt platform
- Building out a semantic layer
These are a good mix of pretty standard data work (have you done your annual migration yet?) and some dbt specific tasks. A good informal eval for the fundamental question for any dev tool: Does it work?
I was pleasantly surprised with my experience in that I didn't have to babysit Wizard or build any additional workflows on top of it. Because it has a native understanding of what a dbt project is, and its ability to set up validation subagents that match the task made it easy for me to just pop in when needed and I didn't have to babysit the whole process and I accomplished all of my objectives.