The dbt MCP server comes to Claude: governed context, one sign-in away

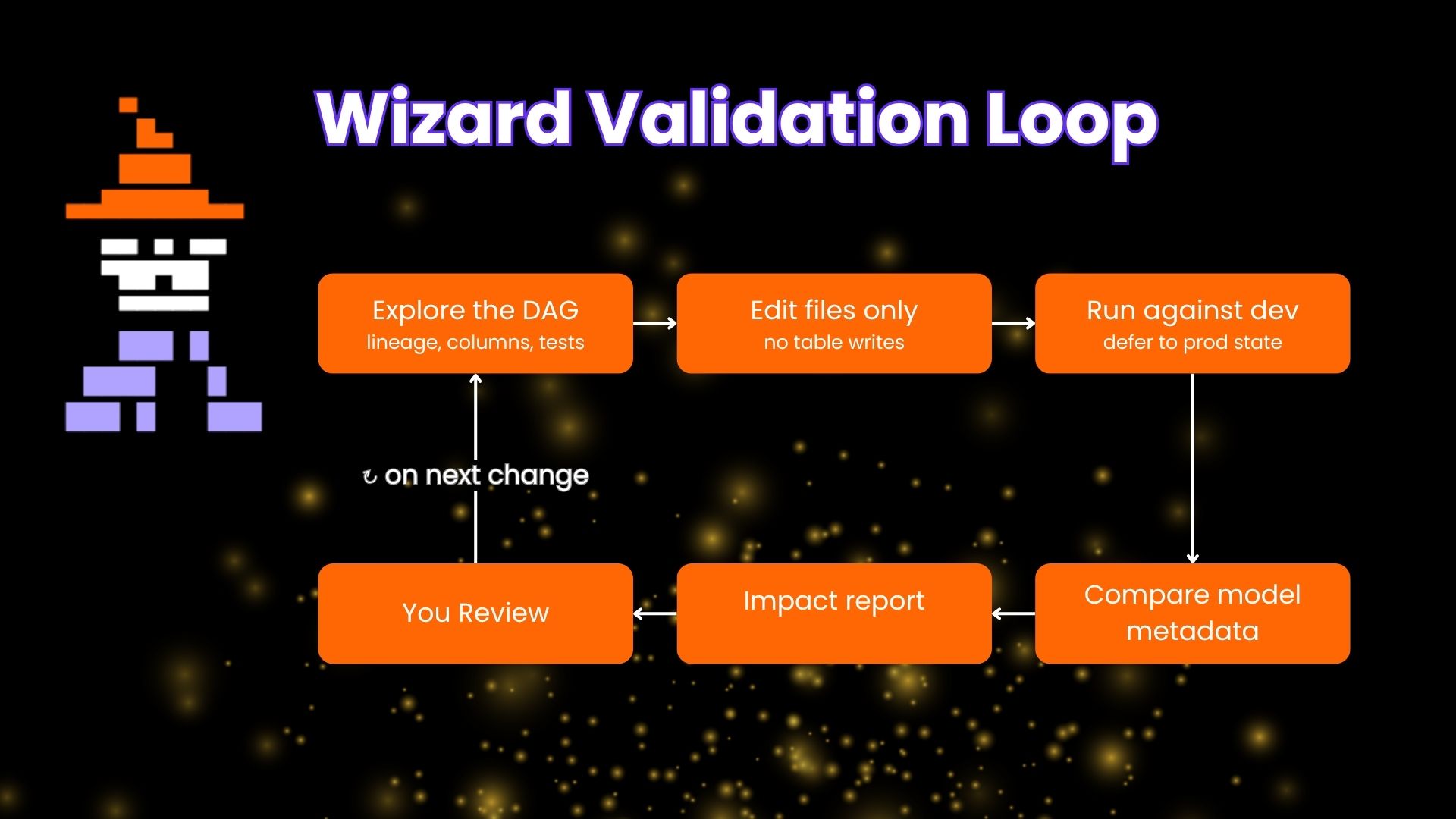
When we open-sourced the dbt MCP server in April 2025, it was an experimental, locally hosted project with a clear thesis behind it: structured data is going to be deeply integrated into AI workflows, and dbt is the layer that provides the governed context those workflows run on. Anthropic has helped validate our thesis. Naturally, it made sense to have a cloud-hosted version with remote OAuth, so you can use it with whatever AI tool you are most comfortable with.
The remote dbt MCP server now runs inside the dbt platform, and you can connect it to Claude in a minute or two by signing in and completing the authentication flow. You add dbt as a connector, approve the access you want, and Claude gains access to your governed data and rich dbt metadata.
This post walks through what the remote server brings to Claude, the types of workflows it fits into for both people and agents, and how the tools compose once they share a conversation.