How to Build a Mature dbt Project from Scratch

[We would love to have] A maturity curve of an end-to-end dbt implementation for each version of dbt .... There are so many features in dbt now but it'd be great to understand, "what is the minimum set of dbt features/components that need to go into a base-level dbt implementation?...and then what are the things that are extra credit?" -Will Weld on dbt Community Slack
One question we hear time and time again is this - what does it look like to progress through the different stages of maturity on a dbt project?
When Will posed this question on Slack, it got me thinking about what it would take to create a framework for dbt project maturity.
As an analytics engineer on the professional services team at dbt Labs, my teammates and I have had the unique opportunity to work on an unusually high number of dbt projects at organizations ranging from tiny startups to Fortune 500 companies and everything in between. From this vantage point, we have gained a unique understanding of the dbt adoption curve - how companies actually implement and expand their usage of dbt.
With every new engagement, we find ourselves working in a project with a unique mix of data challenges. With the explosion in popularity of dbt, and the constant release of new features and capabilities available in the tool, it’s really easy for data teams to go down the rabbit hole of dbt’s shiniest new features before prioritizing the simple ones that will likely be the most immediately impactful to their organization.
A lot of teams find themselves in this position because getting the organizational buy-in for the tool is actually the easy part. Folks have a lot of freedom to go ahead to try out dbt, but once you get started it can be hard to know whether you are taking advantage of all the dbt features that would be right for your project.
In working alongside teams on their dbt journey, we’ve noticed that there tend to be distinct stages of dbt usage that organizations progress through. We’ve come to think of these stages as representing **dbt project maturity. **
We can break the concept of maturity down into two categories. The first is** feature** completeness, or the number of distinct dbt features you are using. The other is** feature depth**, the level of sophistication within the use of individual features. For example, adding the source feature to your project would be increasing the completeness of your project, but adding the source freshness feature to the sources you already defined would be a way to add depth to your project. Walking along this matrix we can watch a teeny tiny baby project grow into a fully mature production grade dbt pipeline.
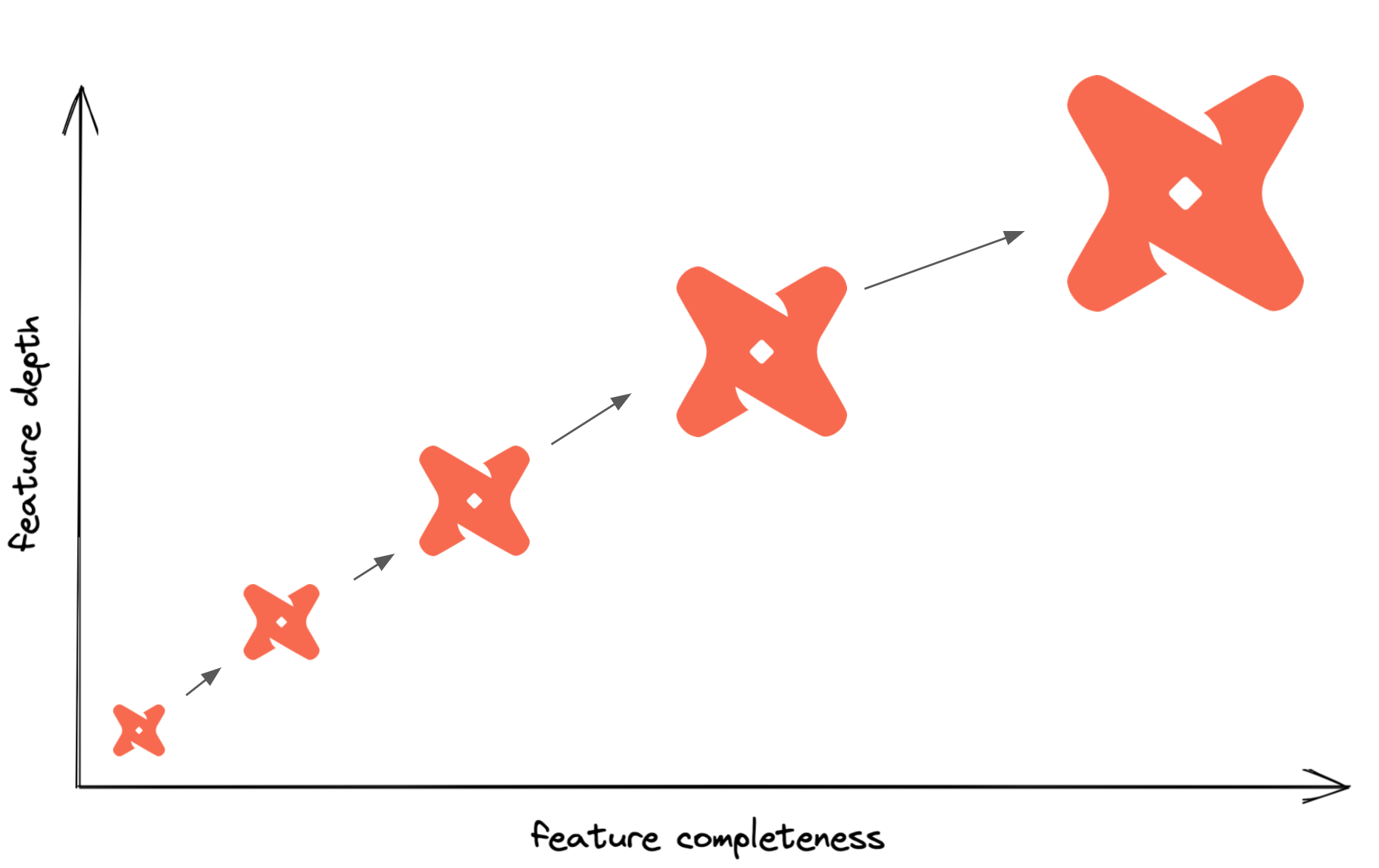
How do we do this?
Let’s pretend that we are an analytics engineer at Seeq Wellness, a hypothetical EHR (electronic health record!) company, and we want to try out dbt to model our patient, doctor and claims data for a critical KPI dashboard. We’re going to create a new dbt project together, and walk through the stages of development, incrementally adding key dbt features as we go along.
We’ve developed a repository that traces the progress in this project; for each step along the maturity curve, there is a subfolder in that repo with a fully functional version of our dbt project at that stage. We’ve also included some sample raw data to add to your warehouse so you can run these projects yourself! You can use this repository to benchmark the maturity of your own dbt project.
Caveats and Assumptions
This is an art, not science!
There are real life use cases where some features get introduced into projects out of the order described here, and that is perfectly reasonable. There are often justifiable reasons to introduce more advanced dbt features earlier in the development cycle.
You are the pace setter
There is no sense of timescale in this presentation! Some teams may mature their project in weeks rather than months. It's more important to think about how features build upon themselves (and each other) rather than how quickly they do so.
Level 1 - Infancy - Running your first model
Key Outcomes
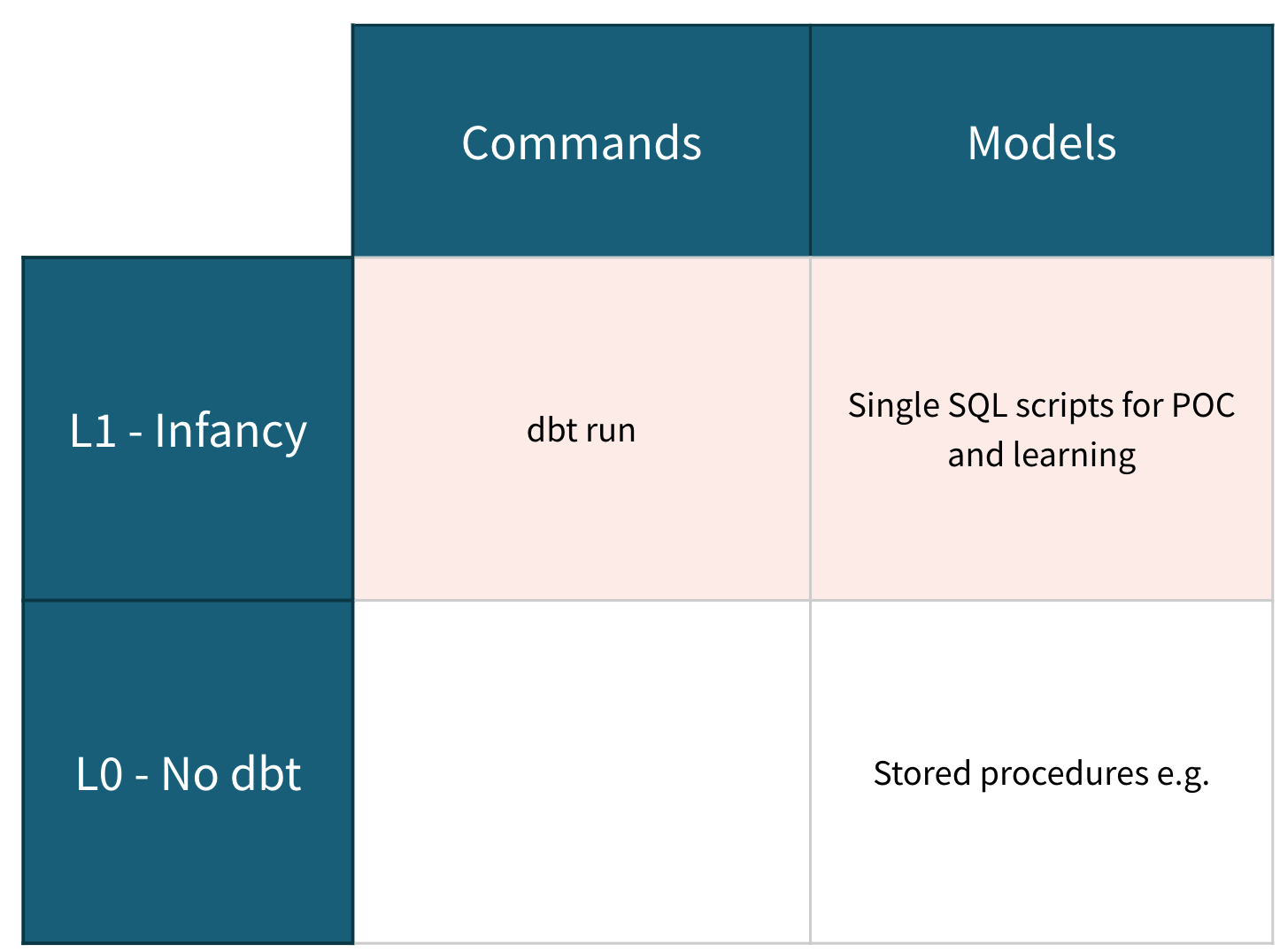
Themes and Goals
Now, I definitely have no authority to speak on what it takes to raise a child, but I understand that a big part of caring for an infant has to do with taking care of its inputs and outputs. The same can be said about a dbt project in this stage!
The goal here is to learn the very basics of interacting with a dbt project; feeding it SQL, getting data objects out of it. We will build on this later, but right now, the important thing to do is create a model in dbt, give dbt a command, and see that it properly produces the view or table in our warehouse that we expect.
In addition to learning the basic pieces of dbt, we're familiarizing ourselves with the modern, version-controlled analytics engineering workflow, and experimenting with how it feels to use it at our organization.
If we decide not to do this, we end up missing out on what the dbt workflow has to offer. If you want to learn more about why we think analytics engineering with dbt is the way to go, I encourage you to read the dbt Viewpoint!
In order to learn the basics, we’re going to port over the SQL file that powers our existing "patient_claim_summary" report that we use in our KPI dashboard in parallel to our old transformation process. We’re not ripping out the old plumbing just yet. In doing so, we're going to try dbt on for size and get used to interfacing with a dbt project.
Project Appearance
We have one single SQL model in our models folder, and really, that's it. At this stage, the README and dbt_project.yml are just artifacts from the dbt init command, and don’t yet have specific documentation or configuration. At this stage of our journey, we just want to get up and running with a functional dbt project.

The most important thing we’re introducing when your project is an infant is the modern, version-controlled, collaborative approach to analytics that dbt offers. The thrill of executing your first successful dbt run is all you need to do to understand how dbt can be massively impactful to your analytics team.
Level 2 - Toddlerhood - Building Modular Data Models
Key Outcomes
-
Configure your first sources
-
Introduce modularity with {{ ref() }} and {{ source() }}
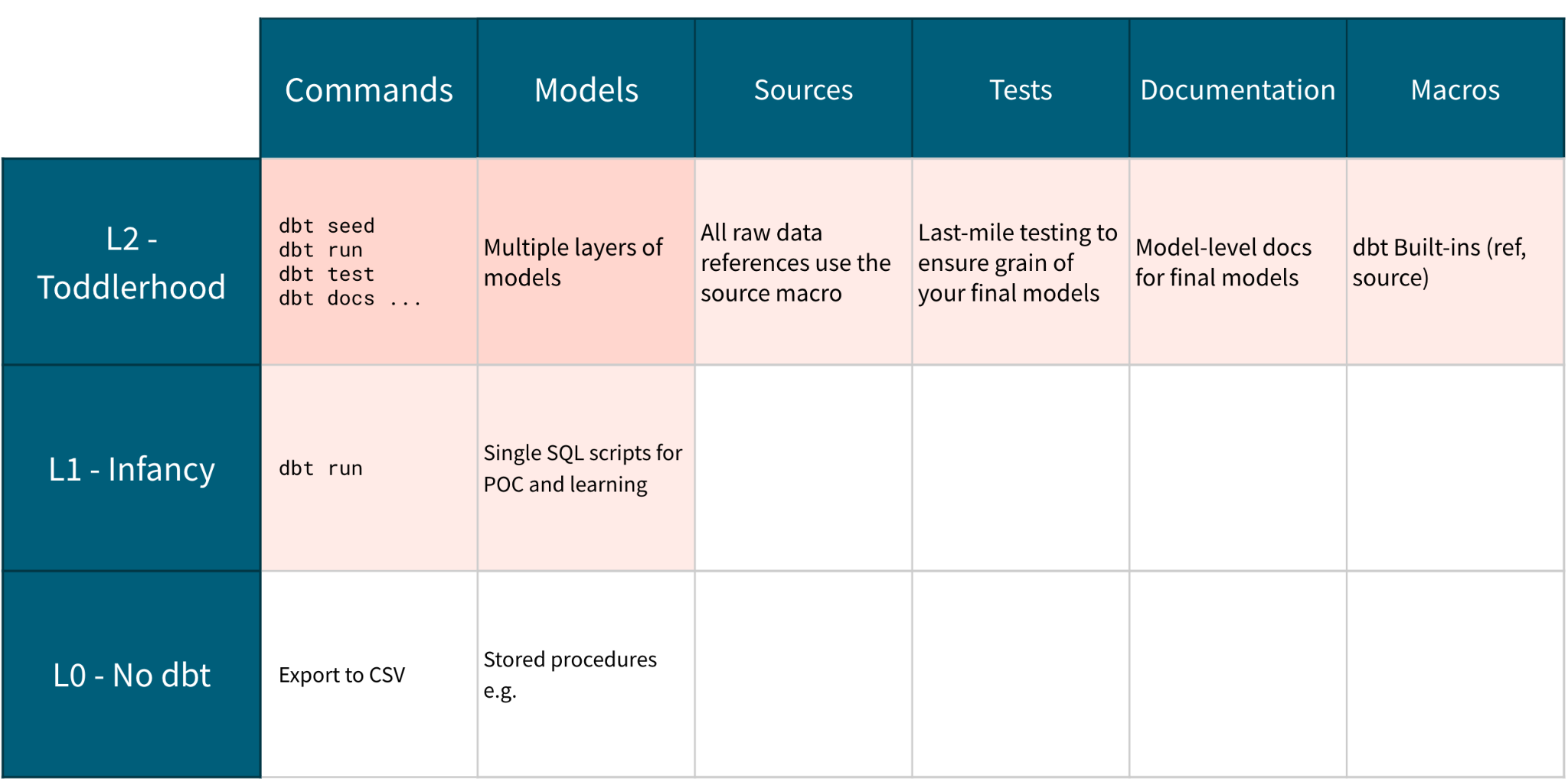
Themes and Goals
Now that we're comfortable translating SQL into a model from our infant project, it's time to teach our project to take its very first steps.
Specifically, now is when it's useful to introduce modularity to our project.
We’re going to:
-
Break out reused code into separate models and use {{ ref() }} to build dependencies
-
Use the {{ source() }} macro to declare our raw data dependencies
-
Dip our toes into testing and documenting our models
Project Appearance
Let's check in on the growth of our project. We've broken some of our logic into its own model — our original script had repetitive logic in subqueries, now it's following a key principle of analytics engineering: Don't Repeat Yourself (DRY). For more information on how to refactor your SQL queries for Modularity - check out our free on-demand course.
We also added our first YML files. Here, we have one YAML file to configure our sources, and one one YAML file to describe our models. We're just starting with basic declarations of our sources, primary key testing using dbt built in tests, and a model-level description -- these are the first steps of a project just learning to walk!
Leveling up from infant to toddler is a huge jump in terms of feature completeness! By adding in sources and refs, we’ve really started to take advantage of what makes dbt special.
Level 3 - Childhood - Developing Standards for Code Collaboration and Maintainability
Key Outcomes
-
Standardize project structure, SQL style guide and model naming conventions in a contribution guide
-
Develop testing and documentation requirements
-
Create a PR template to ensure quality and consistency
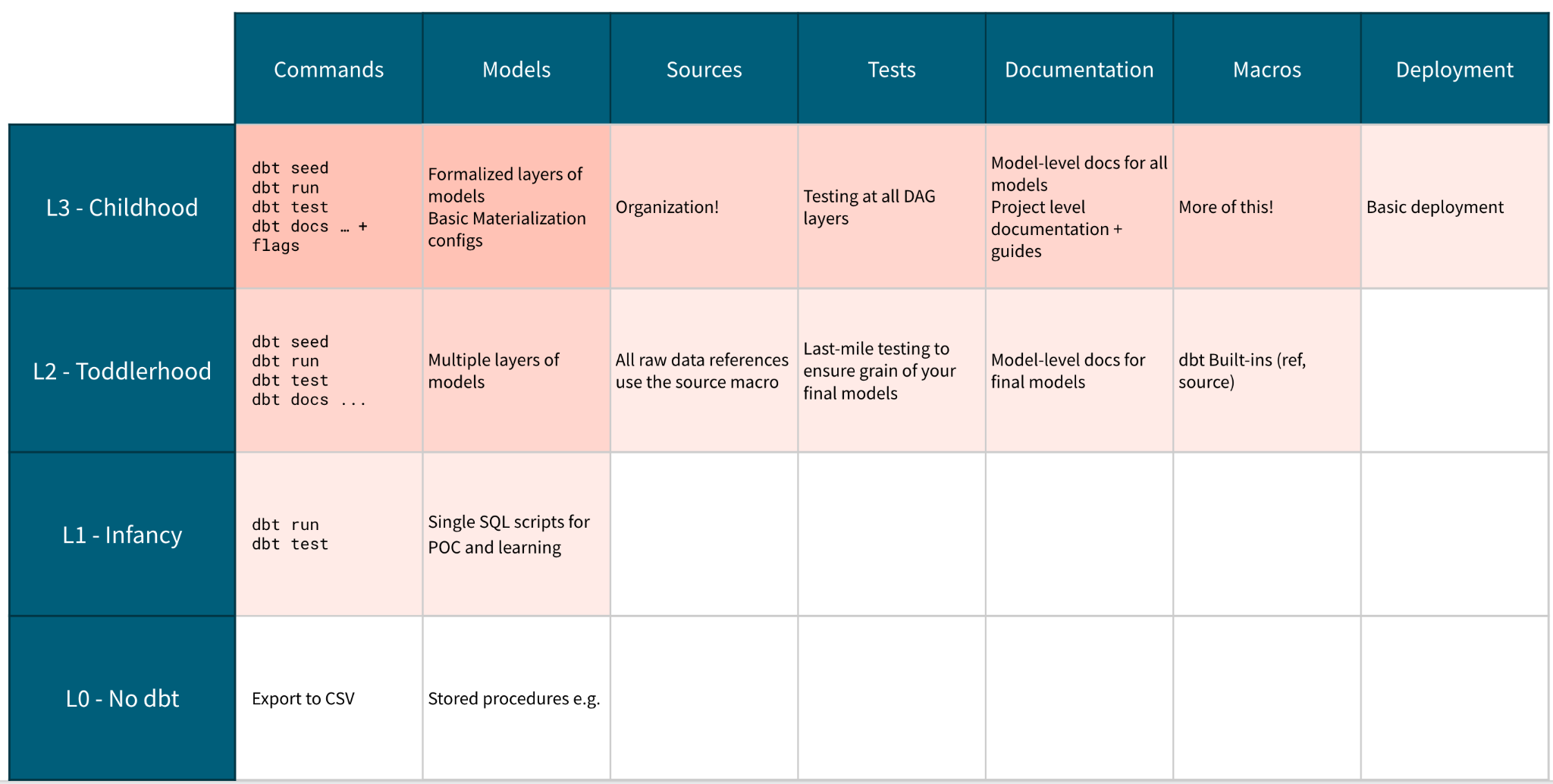
Themes and Goals
We made a huge jump in our feature completeness in the last stage - now it’s time to think about getting the project ready to be used by multiple developers and even deployed into production. The best way to ensure consistency as we start collaborating is to define standards for how we write code and model data then enforce them in the review process. From the data team's perspective, we shouldn't be able to infer who wrote what line of code because one of our teammates uses the dreaded leading comma. Analytics code is an asset, and should be treated as production grade software.
Project Appearance
We've added project-level documentation to our repo for developers to review as they get started in this project. This generally includes:
-
A README with a set up guide with project-specific resources and links out to general dbt resources.
-
A pull request template to make sure we're checking new code against these guidelines every time we want to add new modeling work!
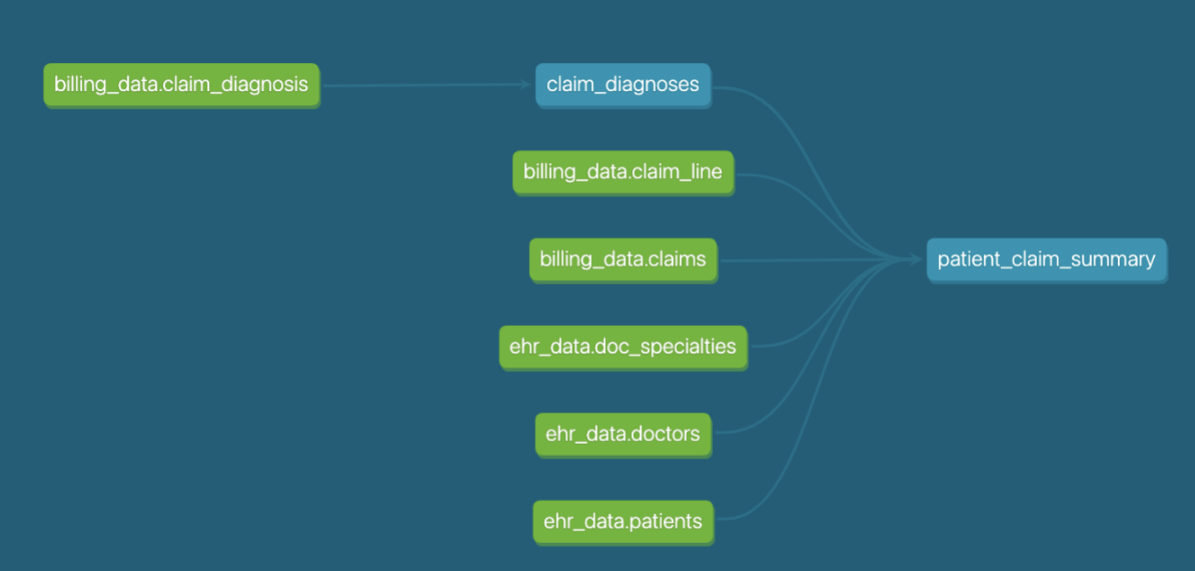
Let's look at our models — we went from a early stage DAG, starting to get a feel for modularity, to a clean, standardized and logically organized DAG — we can now see logical layers of modeling that correspond to the file tree structure we saw before — we can even see the model naming conventions lining up with these layers (stg, int, fct). Defining the standards in how we organize our models in our project level has resulted in a cleaner, easier to understand DAG too!
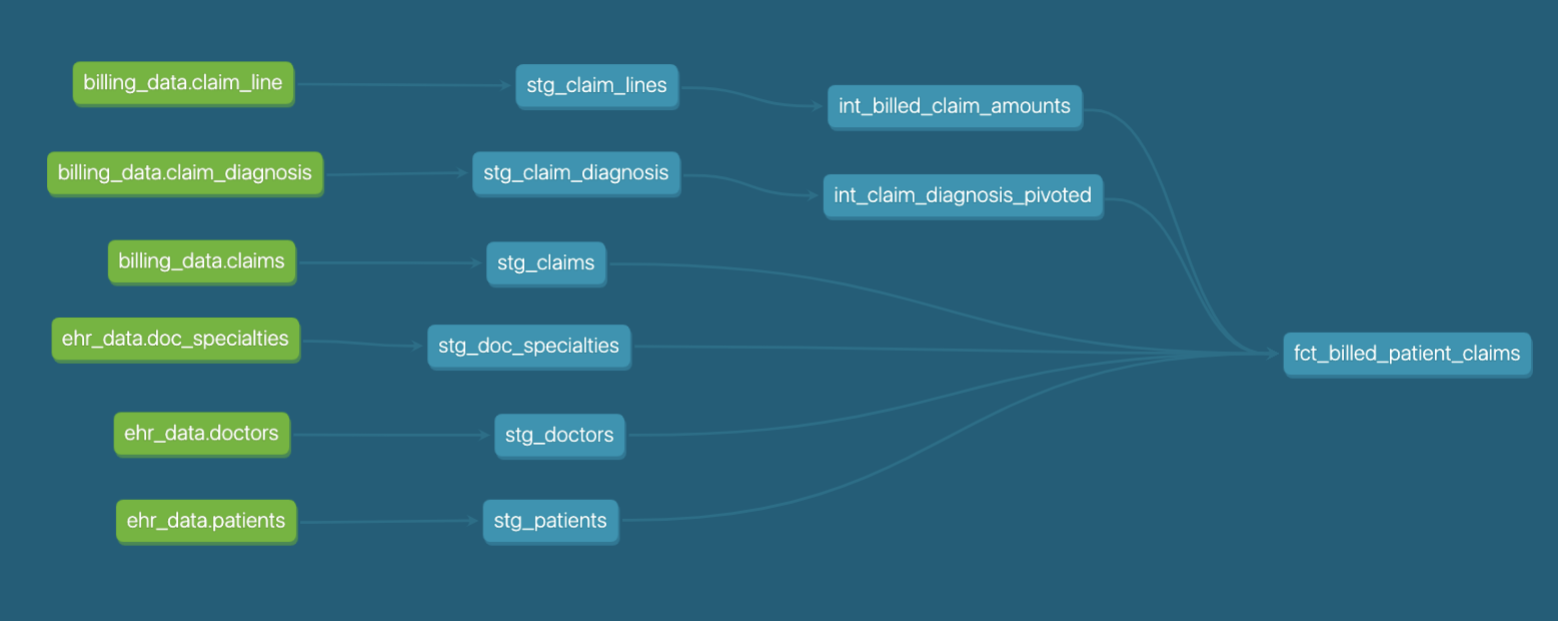
Even though we haven't changed the function of a lot of our features codifying and standardizing the use of these features is a huge step forward for project maturity. Getting to this level of maturity is when we generally start to think about running this project in production. With these guardrails in place, we can be confident our project isn’t going to fall out of bed at night and hurt itself -- it’s ready to take on a little bit of independence!
Level 4 - Adolescence - Increasing Flexibility
Key Outcomes
-
Leverage code from dbt packages
-
Increase model flexibility and scope of project
-
Reduce dbt production build times with advanced materializations
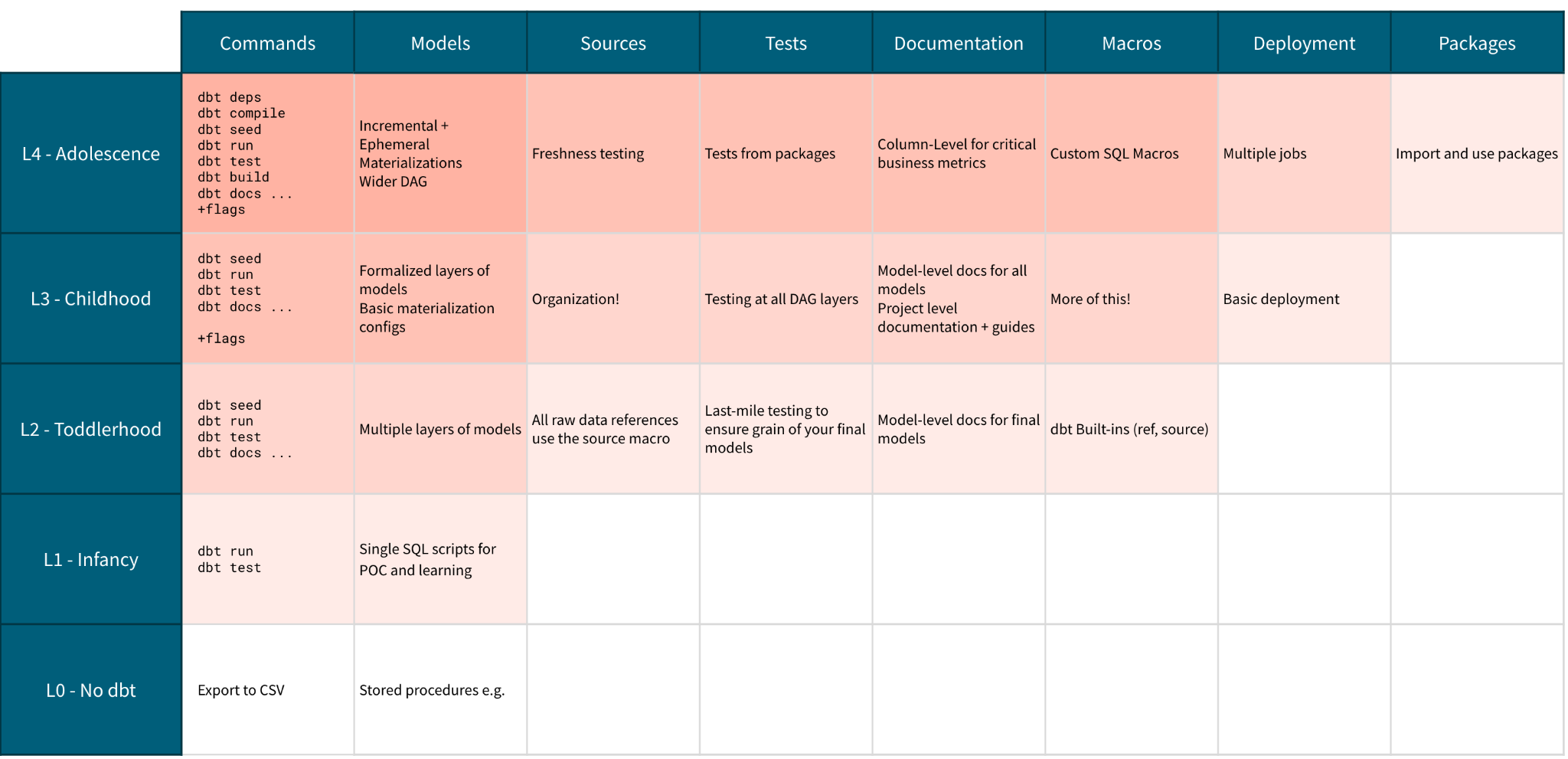
Themes and Goals
Wow, our project is growing up fast — it's heading off into the world, learning new things, getting into trouble (don't worry that's just normal teen stuff). Our project is finally starting to think about its place in the world and in the greater dbt ecosystem. It's also starting to get buy-in from our stakeholders, and they want *more. *At this stage, learning how to do some more advanced tricks with dbt can allow us to think beyond the business logic we’re defining, and instead think more about *how *that business logic is built. Where can we make this project more efficient? How can we start serving up more information about our data to our stakeholders?
I want to also call out that a "feature" to introduce at this stage is engagement with the dbt community — in reality, I'm hopeful that we'd have been doing that this whole time, but thinking about opening up your projects to community-supported packages, as well as using the braintrust in the community Slack as a jumping off point for solving some of your data problems starts to really blossom around this point in the project lifecycle.
Project Appearance
We can see the major development at this stage is adding additional models that make our original claims report a lot more flexible -- we had only shown our users a subset of patient and doctor information in our fact model. Now, we have a more Kimball-ish-style marts setup, and we can leave selecting the dimensions up to our BI tool.

Other enhancements not seen in the DAG at this stage include new custom macros to make SQL writing more dynamic and less repetitive. We can also see a packages.yml file, and we can start leveraging tests, macros, and even models developed by the dbt community. Leveraging package code is a key way to shrink our development time! We've also leveled up to using incremental logic for our largest data sets to speed up our runs and deliver insights faster. We're also interested in surfacing a little bit of the metadata from our project — we can start by enhancing our marts with data about its recency by enabling the source freshness feature. Knowing that the data in our dashboard is up to date and reliable can massively improve consumer confidence in our stack.
We've spent this level focused on deepening and optimizing our feature set — we haven't introduced much more feature completeness except for SQL macros and the use of packages. Now, we're strong enough dbt developers that our time and energy is focused on taking a step back from making this project work to thinking about how to make it work well.
Level 5 - Adulthood - Solidifying Relationships
Key Outcomes
-
Formalize dbt’s relationship to BI with exposures!
-
Advanced use of metadata
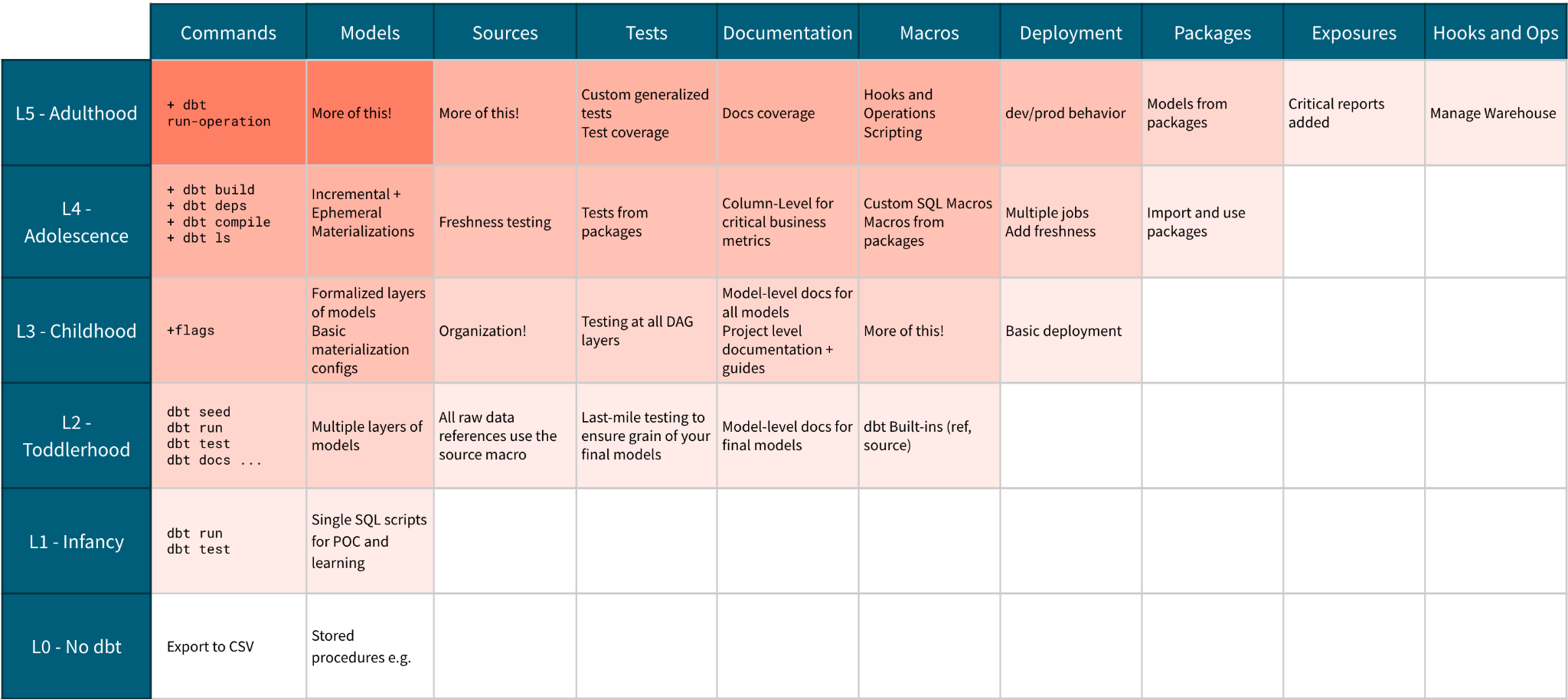
Themes and Goals
In adulthood, we're turning our gaze even further inward. Our dbt project itself is independent enough to start asking itself the big questions! What does it mean to be a dbt project in the year 2021? How have I been changing? How am I relating to my peers?
At this point, like we started to do in adolescence, we are going to focus on thinking about dbt-as-a-product, and how that product interacts with the rest of our stack. We are sinking our roots a layer deeper.
Project Appearance
We see the biggest jump from the previous stage in the macros folder. By introducing advanced macros that go beyond simple SQL templating, we’re able to have dbt deepen its relationship to our warehouse. Now we can have dbt manage things like custom schema behavior, run post hooks to drop retired models and dynamically orchestrate object permission controls; dbt itself can become your command post for warehouse management.
Additionally, we’ve added an exposures file to formally define the use of our marts models in our BI tool. Exposures are the most mature way to declare the data team's contracts with data consumers. We now have close to end-to-end awareness of the data lineage — we know what data our project depends on, whether it's fresh, how it is transformed in our dbt models, and finally where it’s consumed in reports. Now, we can also know which of our key reports are impacted if and when we hit an error at any point in this flow.
That end to end awareness is visible on the DAG too — we can see the dashboard we declared in our exposures file here in orange!
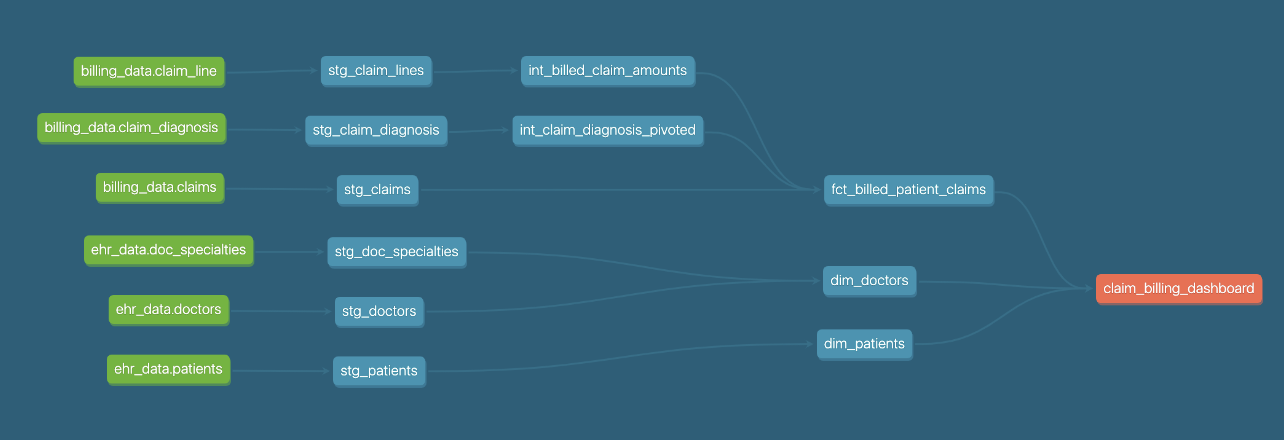
Making the jump to thinking about metadata is a really powerful way to find areas for improvement in your project. For example, you can develop macros to measure things like your test coverage, and test to model ratio. You can look into packages like dbt_meta_testing to ensure your hitting minimum testing and documentation requirements.
If you're on cloud, you can do all of these and more in a more programmatic way with the metadata API — you can dig into model runtimes and bottlenecks, and leverage exposures directly in your BI tool to bring that metadata to your end users! Neat!
Conclusion
Life is truly a highway. We’ve traced the growth of the Seeq Wellness dbt project from birth to mid-life crisis, and we have so much growing left to do. Hopefully you can use this framework as a jumping off point to find areas in your own projects where it could stand to grow up a bit. We would love to hear from you in the repo if there are any questions, disagreements, or enhancements you’d like to see here! Another huge thank you to Will Weld, who was instrumental in developing this framework!