What is ELT (Extract, Load, Transform)?
ELT has emerged as a paradigm for how to manage information flows in a modern data warehouse. This represents a fundamental shift from how data previously was handled when Extract, Transform, Load (ETL) was the data workflow most companies implemented.
Transitioning from ETL to ELT means that you no longer have to capture your transformations during the initial loading of the data into your data warehouse. Rather, you are able to load all of your data, then build transformations on top of it. Data teams report that the ELT workflow has several advantages over the traditional ETL workflow which we’ll go over in-depth later in this glossary.
How ELT works
In an ELT process, data is extracted from data sources, loaded into a target data platform, and finally transformed for analytics use. We’ll go over the three components (extract, load, transform) in detail here.
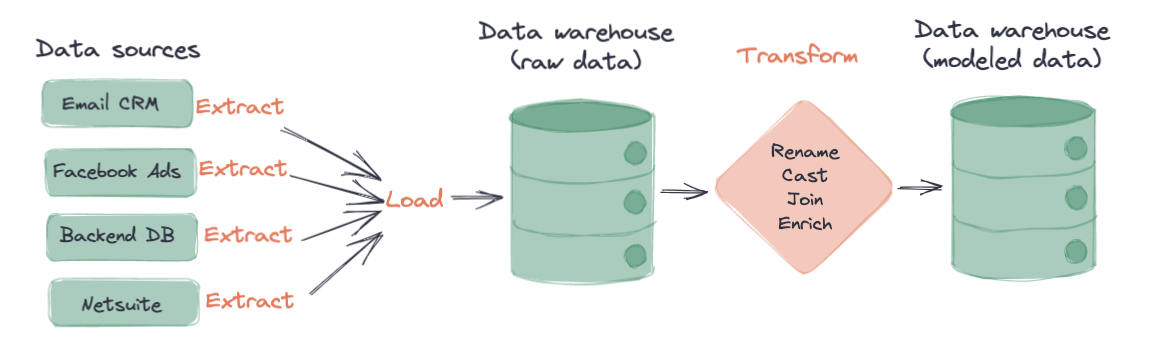
Extract
In the extraction process, data is extracted from multiple data sources. The data extracted is, for the most part, data that teams eventually want to use for analytics work. Some examples of data sources can include:
- Backend application databases
- Marketing platforms
- Email and sales CRMs
- and more!
Accessing these data sources using Application Programming Interface (API) calls can be a challenge for individuals and teams who don't have the technical expertise or resources to create their own scripts and automated processes. However, the recent development of certain open-source and Software as a Service (SaaS) products has removed the need for this custom development work. By establishing the option to create and manage pipelines in an automated way, you can extract the data from data sources and load it into data warehouses via a user interface.
Since not every data source will integrate with SaaS tools for extraction and loading, it’s sometimes inevitable that teams will write custom ingestion scripts in addition to their SaaS tools.
Load
During the loading stage, data that was extracted is loaded into the target data warehouse. Some examples of modern data warehouses include Snowflake, Amazon Redshift, and Google BigQuery. Examples of other data storage platforms include data lakes such as Databricks’s Data Lakes. Most of the SaaS applications that extract data from your data sources will also load it into your target data warehouse. Custom or in-house extraction and load processes usually require strong data engineering and technical skills.
At this point in the ELT process, the data is mostly unchanged from its point of extraction. If you use an extraction and loading tool like Fivetran, there may have been some light normalization on your data. But for all intents and purposes, the data loaded into your data warehouse at this stage is in its raw format.
Transform
In the final transformation step, the raw data that has been loaded into your data warehouse is finally ready for modeling! When you first look at this data, you may notice a few things about it…
- Column names may or may not be clear
- Some columns are potentially the incorrect data type
- Tables are not joined to other tables
- Timestamps may be in the incorrect timezone for your reporting
- JSON fields may need to be unnested
- Tables may be missing primary keys
- And more!
...hence the need for transformation! During the transformation process, data from your data sources is usually:
- Lightly Transformed: Fields are cast correctly, timestamp fields’ timezones are made uniform, tables and fields are renamed appropriately, and more.
- Heavily Transformed: Business logic is added, appropriate materializations are established, data is joined together, etc.
- QA’d: Data is tested according to business standards. In this step, data teams may ensure primary keys are unique, model relations match-up, column values are appropriate, and more.
Common ways to transform your data include leveraging modern technologies such as dbt, writing custom SQL scripts that are automated by a scheduler, utilizing stored procedures, and more.
ELT vs ETL
The primary difference between the traditional ETL and the modern ELT workflow is when data transformation and loading take place. In ETL workflows, data extracted from data sources is transformed prior to being loaded into target data platforms. Newer ELT workflows have data being transformed after being loaded into the data platform of choice. Why is this such a big deal?
| ELT | ETL | |
|---|---|---|
| Programming skills required | Often little to no code to extract and load data into your data warehouse. | Often requires custom scripts or considerable data engineering lift to extract and transform data prior to load. |
| Separation of concerns | Extraction, load, and transformation layers can be explicitly separated out by different products. | ETL processes are often encapsulated in one product. |
| Distribution of transformations | Since transformations take place last, there is greater flexibility in the modeling process. Worry first about getting your data in one place, then you have time to explore the data to understand the best way to transform it. | Because transformation occurs before data is loaded into the target location, teams must conduct thorough work prior to make sure data is transformed properly. Heavy transformations often take place downstream in the BI layer. |
| Data team distribution | ELT workflows empower data team members who know SQL to create their own extraction and loading pipelines and transformations. | ETL workflows often require teams with greater technical skill to create and maintain pipelines. |
Why has ELT adoption grown so quickly in recent years? A few reasons:
- The abundance of cheap cloud storage with modern data warehouses. The creation of modern data warehouses such Redshift and Snowflake has made it so teams of all sizes can store and scale their data at a more efficient cost. This was a huge enabler for the ELT workflow.
- The development of low-code or no-code data extractors and loaders. Products that require little technical expertise such as Fivetran and Stitch, which can extract data from many data sources and load it into many different data warehouses, have helped lower the barrier of entry to the ELT workflow. Data teams can now relieve some of the data engineering lift needed to extract data and create complex transformations.
- A true code-based, version-controlled transformation layer with the development of dbt. Prior to the development of dbt, there was no singular transformation layer product. dbt helps data analysts apply software engineering best practices (version control, CI/CD, and testing) to data transformation, ultimately allowing for anyone who knows SQL to be a part of the ELT process.
- Increased compatibility between ELT layers and technology in recent years. With the expansion of extraction, loading, and transformation layers that integrate closely together and with cloud storage, the ELT workflow has never been more accessible. For example, Fivetran creates and maintains dbt packages to help write dbt transformations for the data sources they connect to.
Benefits of ELT
You often hear about the benefits of the ELT workflow to data, but you can sometimes forget to talk about the benefits it brings to people. There are a variety of benefits that this workflow brings to the actual data (which we’ll outline in detail below), such as the ability to recreate historical transformations, test data and data models, and more. We'll also want to use this section to emphasize the empowerment the ELT workflow brings to both data team members and business stakeholders.
ELT benefit #1: Data as code
Ok we said it earlier: The ELT workflow allows data teams to function like software engineers. But what does this really mean? How does it actually impact your data?
Analytics code can now follow the same best practices as software code
At its core, data transformations that occur last in a data pipeline allow for code-based and version-controlled transformations. These two factors alone permit data team members to:
- Easily recreate historical transformations by rolling back commits
- Establish code-based tests
- Implement CI/CD workflows
- Document data models like typical software code.
Scaling, made sustainable
As your business grows, the number of data sources correspondingly increases along with it. As such, so do the number of transformations and models needed for your business. Managing a high number of transformations without version control or automation is not scalable.
The ELT workflow capitalizes on transformations occurring last to provide flexibility and software engineering best practices to data transformation. Instead of having to worry about how your extraction scripts scale as your data increases, data can be extracted and loaded automatically with a few clicks.
ELT benefit #2: Bring the power to the people
The ELT workflow opens up a world of opportunity for the people that work on that data, not just the data itself.
Empowers data team members
Data analysts, analytics engineers, and even data scientists no longer have to be dependent on data engineers to create custom pipelines and models. Instead, they can use point-and-click products such as Fivetran and Airbyte to extract and load the data for them.
Having the transformation as the final step in the ELT workflow also allows data folks to leverage their understanding of the data and SQL to focus more on actually modeling the data.
Promotes greater transparency for end busines users
Data teams can expose the version-controlled code used to transform data for analytics to end business users by no longer having transformations hidden in the ETL process. Instead of having to manually respond to the common question, “How is this data generated?” data folks can direct business users to documentation and repositories. Having end business users involved or viewing the data transformations promote greater collaboration and awareness between business and data folks.
ELT tools
As mentioned earlier, the recent development of certain technologies and products has helped lower the barrier of entry to implementing the ELT workflow. Most of these new products act as one or two parts of the ELT process, but some have crossover across all three parts. We’ll outline some of the current tools in the ELT ecosystem below.
| Product | E/L/T? | Description | Open source option? |
|---|---|---|---|
| Fivetran/HVR | E, some T, L | Fivetran is a SaaS company that helps data teams extract, load, and perform some transformation on their data. Fivetran easily integrates with modern data warehouses and dbt. They also offer transformations that leverage dbt Core. | ❌ |
| Stitch by Talend | E, L | Stitch (part of Talend) is another SaaS product that has many data connectors to extract data and load it into data warehouses. | ❌ |
| Airbyte | E, L | Airbyte is an open-source and cloud service that allows teams to create data extraction and load pipelines. | ✅ |
| Funnel | E, some T, L | Funnel is another product that can extract and load data. Funnel’s data connectors are primarily focused around marketing data sources. | ❌ |
| dbt | T | dbt is the transformation tool that enables data analysts and engineers to transform, test, and document data in the cloud data warehouse. dbt offers both an open-source and cloud-based product. | ✅ |
Conclusion
The past few years have been a whirlwind for the data world. The increased accessibility and affordability of cloud warehouses, no-code data extractors and loaders, and a true transformation layer with dbt has allowed for the ELT workflow to become the preferred analytics workflow. ETL predates ELT and differs in when data is transformed. In both processes, data is first extracted from different sources. However, in ELT processes, data is loaded into the target data platform and then transformed. The ELT workflow ultimately allows for data team members to extract, load, and model their own data in a flexible, accessible, and scalable way.
Further reading
Here's some of our favorite content about the ELT workflow: