What is ETL (Extract, Transform, Load)?
ETL, or “Extract, Transform, Load”, is the process of first extracting data from a data source, transforming it, and then loading it into a target data warehouse. In ETL workflows, much of the meaningful data transformation occurs outside this primary pipeline in a downstream business intelligence (BI) platform.
ETL is contrasted with the newer ELT (Extract, Load, Transform) workflow, where transformation occurs after data has been loaded into the target data warehouse. In many ways, the ETL workflow could have been renamed the ETLT workflow, because a considerable portion of meaningful data transformations happen outside the data pipeline. The same transformations can occur in both ETL and ELT workflows, the primary difference is when (inside or outside the primary ETL workflow) and where the data is transformed (ETL platform/BI tool/data warehouse).
It’s important to talk about ETL and understand how it works, where it provides value, and how it can hold people back. If you don’t talk about the benefits and drawbacks of systems, how can you expect to improve them?
How ETL works
In an ETL process, data is first extracted from a source, transformed, and then loaded into a target data platform. We’ll go into greater depth for all three steps below.
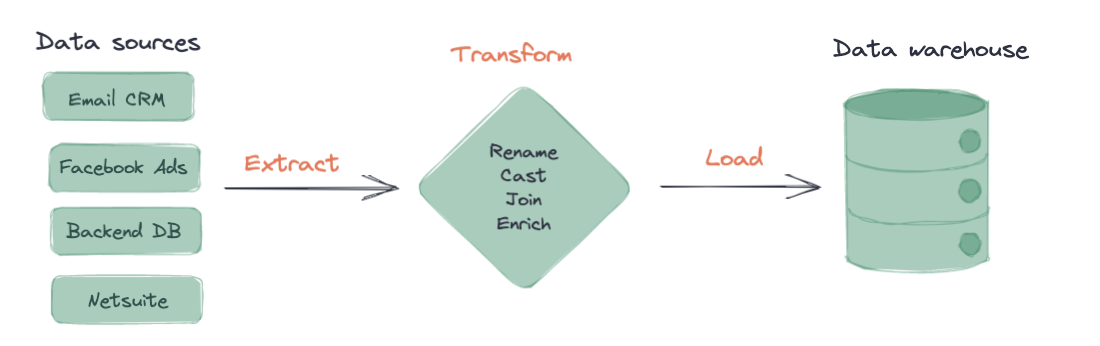
Extract
In this first step, data is extracted from different data sources. Data that is extracted at this stage is likely going to be eventually used by end business users to make decisions. Some examples of these data sources include:
- Ad platforms (Facebook Ads, Google Ads, etc.)
- Backend application databases
- Sales CRMs
- And more!
To actually get this data, data engineers may write custom scripts that make Application Programming Interface (API) calls to extract all the relevant data. Because making and automating these API calls gets harder as data sources and data volume grows, this method of extraction often requires strong technical skills. In addition, these extraction scripts also involve considerable maintenance since APIs change relatively often. Data engineers are often incredibly competent at using different programming languages such as Python and Java. Data teams can also extract from these data sources with open source and Software as a Service (SaaS) products.
Transform
At this stage, the raw data that has been extracted is normalized and modeled. In ETL workflows, much of the actual meaningful business logic, metric calculations, and entity joins tend to happen further down in a downstream BI platform. As a result, the transformation stage here is focused on data cleanup and normalization – renaming of columns, correct casting of fields, timestamp conversions.
To actually transform the data, there’s two primary methods teams will use:
- Custom solutions: In this solution, data teams (typically data engineers on the team), will write custom scripts and create automated pipelines to transform the data. Unlike ELT transformations that typically use SQL for modeling, ETL transformations are often written in other programming languages such as Python or Scala. Data engineers may leverage technologies such as Apache Spark or Hadoop at this point to help process large volumes of data.
- ETL products: There are ETL products that will extract, transform, and load your data in one platform. These tools often involve little to no code and instead use Graphical User Interfaces (GUI) to create pipelines and transformations.
Load
In the final stage, the transformed data is loaded into your target data warehouse. Once this transformed data is in its final destination, it’s most commonly exposed to end business users either in a BI tool or in the data warehouse directly.
The ETL workflow implies that your raw data does not live in your data warehouse. Because transformations occur before load, only transformed data lives in your data warehouse in the ETL process. This can make it harder to ensure that transformations are performing the correct functionality.
How ETL is being used
While ELT adoption is growing, we still see ETL use cases for processing large volumes of data and adhering to strong data governance principles.
ETL to efficiently normalize large volumes of data
ETL can be an efficient way to perform simple normalizations across large data sets. Doing these lighter transformations across a large volume of data during loading can help get the data formatted properly and quickly for downstream use. In addition, end business users sometimes need quick access to raw or somewhat normalized data. Through an ETL workflow, data teams can conduct lightweight transformations on data sources and quickly expose them in their target data warehouse and downstream BI tool.
ETL for hashing PII prior to load
Some companies will want to mask, hash, or remove PII values before it enters their data warehouse. In an ETL workflow, teams can transform PII to hashed values or remove them completely during the loading process. This limits where PII is available or accessible in an organization’s data warehouse.
ETL challenges
There are reasons ETL has persisted as a workflow for over twenty years. However, there are also reasons why there’s been such immense innovation in this part of the data world in the past decade. From our perspective, the technical and human limitations we describe below are some of the reasons ELT has surpassed ETL as the preferred workflow.
ETL challenge #1: Technical limitations
Limited or lack of version control
When transformations exist as standalone scripts or deeply woven in ETL products, it can be hard to version control the transformations. Not having version control on transformation as code means that data teams can’t easily recreate or rollback historical transformations and perform code reviews.
Immense amount of business logic living in BI tools
Some teams with ETL workflows only implement much of their business logic in their BI platform versus earlier in their transformation phase. While most organizations have some business logic in their BI tools, an excess of this logic downstream can make rendering data in the BI tool incredibly slow and potentially hard to track if the code in the BI tool is not version controlled or exposed in documentation.
Challenging QA processes
While data quality testing can be done in ETL processes, not having the raw data living somewhere in the data warehouse inevitably makes it harder to ensure data models are performing the correct functionality. In addition, quality control continually gets harder as the number of data sources and pipelines within your system grows.
ETL challenge #2: Human limitations
Data analysts can be excluded from ETL work
Because ETL workflows often involve incredibly technical processes, they've restricted data analysts from being involved in the data workflow process. One of the greatest strengths of data analysts is their knowledge of the data and SQL, and when extractions and transformations involve unfamiliar code or applications, they and their expertise can be left out of the process. Data analysts and scientists also become dependent on other people to create the schemas, tables, and datasets they need for their work.
Business users are kept in the dark
Transformations and business logic can often be buried deep in custom scripts, ETL tools, and BI platforms. At the end of the day, this can hurt business users: They're kept out of the data modeling process and have limited views into how data transformation takes place. As a result, end business users often have little clarity on data definition, quality, and freshness, which ultimately can decrease trust in the data and data team.
ETL vs ELT
You may read other articles or technical documents that use ETL and ELT interchangeably. On paper, the only difference is the order in which the T and the L appear. However, this mere switching of letters dramatically changes the way data exists in and flows through a business’ system.
In both processes, data from different data sources is extracted in similar ways. However, in ELT, data is then directly loaded into the target data platform versus being transformed in ETL. Now, via ELT workflows, both raw and transformed data can live in a data warehouse. In ELT workflows, data folks have the flexibility to model the data after they’ve had the opportunity to explore and analyze the raw data. ETL workflows can be more constraining since transformations happen immediately after extraction. We break down some of the other major differences between the two below:
| ELT | ETL | |
|---|---|---|
| Programming skills required | Often requires little to no code to extract and load data into your data warehouse. | Often requires custom scripts or considerable data engineering lift to extract and transform data prior to load. |
| Separation of concerns | Extraction, load, and transformation layers can be explicitly separated out by different products. | ETL processes are often encapsulated in one product. |
| Distribution of transformations | Since transformations take place last, there is greater flexibility in the modeling process. Worry first about getting your data in one place, then you have time to explore the data to understand the best way to transform it. | Because transformation occurs before data is loaded into the target location, teams must conduct thorough work prior to make sure data is transformed properly. Heavy transformations often take place downstream in the BI layer. |
| Data team roles | ELT workflows empower data team members who know SQL to create their own extraction and loading pipelines and transformations. | ETL workflows often require teams with greater technical skill to create and maintain pipelines. |
While ELT is growing in adoption, it’s still important to talk about when ETL might be appropriate and where you'll see challenges with the ETL workflow.
ETL tools
There exists a variety of ETL technologies to help teams get data into their data warehouse. A good portion of ETL tools on the market today are geared toward enterprise businesses and teams, but there are some that are also applicable for smaller organizations.
| Platform | E/T/L? | Description | Open source option? |
|---|---|---|---|
| Informatica | E, T, L | An all-purpose ETL platform that supports low or no-code extraction, transformations and loading. Informatica also offers a broad suite of data management solutions beyond ETL and is often leveraged by enterprise organizations. | ❌ |
| Integrate.io | E, T, L | A newer ETL product focused on both low-code ETL as well as reverse ETL pipelines. | ❌ |
| Matillion | E, T, L | Matillion is an end-to-end ETL solution with a variety of native data connectors and GUI-based transformations. | ❌ |
| Microsoft SISS | E, T, L | Microsoft’s SQL Server Integration Services (SISS) offers a robust, GUI-based platform for ETL services. SISS is often used by larger enterprise teams. | ❌ |
| Talend Open Studio | E, T, L | An open source suite of GUI-based ETL tools. | ✅ |
Conclusion
ETL, or “Extract, Transform, Load,” is the process of extracting data from different data sources, transforming it, and loading that transformed data into a data warehouse. ETL typically supports lighter transformations during the phase prior to loading and more meaningful transformations to take place in downstream BI tools. We’re seeing now that ETL is fading out and the newer ELT workflow is replacing it as a practice for many data teams. However, it’s important to note that ETL allowed us to get us to where we are today: Capable of building workflows that extract data within simple UIs, store data in scalable cloud data warehouses, and write data transformations like software engineers.
Further Reading
Please check out some of our favorites reads regarding ETL and ELT below: