Reverse ETL
Reverse ETL is the process of getting your transformed data stored in your data warehouse to end business platforms, such as sales CRMs and ad platforms. Once in an end platform, that data is often used to drive meaningful business actions, such as creating custom audiences in ad platforms, personalizing email campaigns, or supplementing data in a sales CRM. You may also hear about reverse ETL referred to as operational analytics or data activation.
Reverse ETL efforts typically happen after data teams have set up their modern data stack and ultimately have a consistent and automated way to extract, load, and transform data. Data teams are also often responsible for setting up the pipelines to send down data to business platforms, and business users are typically responsible for using the data once it gets to their end platform.
Ultimately, reverse ETL is a way to put data where the work is already happening, support self-service efforts, and help business users derive real action out of their data.
How reverse ETL works
In the reverse ETL process, transformed data is synced from a data warehouse to external tools in order to be leveraged by different business teams.
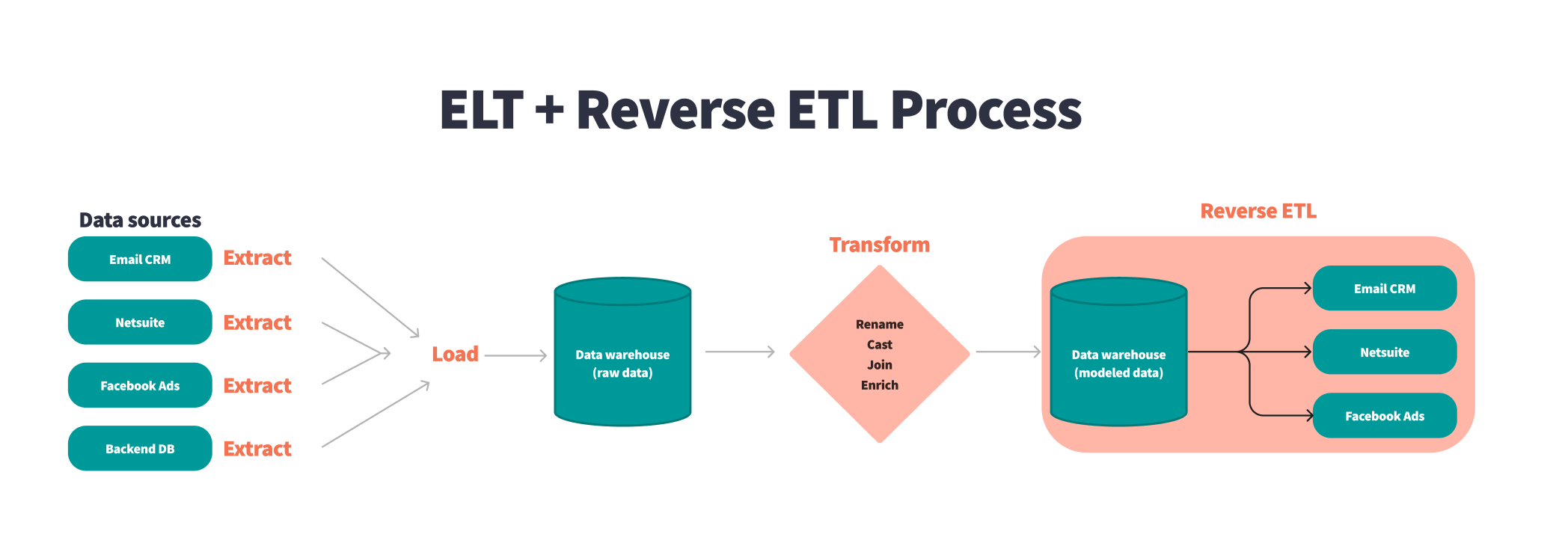
The power of reverse ETL comes from sending down already transformed data to business platforms. Raw data, while beautiful in its own way, typically lacks the structure, aggregations, and aliasing to be useful for end business users off the bat. After data teams transform data for business use in ELT pipelines, typically to expose in an end business intelligence (BI) tool, they can also send this cleaned and meaningful data to other platforms where business users can derive value using reverse ETL tools.
Data teams can choose to write additional transformations that may need to happen for end business tools in reverse ETL tools themselves or by creating additional models in dbt.
Why use reverse ETL?
There’s a few reasons why your team may want to consider using reverse ETL:
Putting data where the work is happening
While most data teams would love it if business users spent a significant portion of their time in their BI tool, that’s neither practical nor necessarily the most efficient use of their time. In the real world, many business users will spend some time in a BI tool, identify the data that could be useful in a platform they spend a significant amount of time in, and work with the data team to get that data where they need it. Users feel comfortable and confident in the systems they use everyday—why not put the data in the places that allow them to thrive?
Manipulating data to fit end platform requirements
Reverse ETL helps you to put data your business users need in the format their end tool expects. Oftentimes, end platforms expect data fields to be named or cast in a certain way. Instead of business users having to manually input those values in the correct format, you can transform your data using a product like dbt or directly in a reverse ETL tool itself, and sync down that data in an automated way.
Supporting self-service efforts
By sending down data-team approved data in reverse ETL pipelines, your business users have the flexibility to use that data however they see fit. Soon, your business users will be making audiences, testing personalization efforts, and running their end platform like a well-oiled, data-powered machine.
Reverse ETL use cases
Just as there are almost endless opportunities with data, there are many potential different use cases for reverse ETL. We won’t go into every possible option, but we’ll cover some of the common use cases that exist for reverse ETL efforts.
Personalization
Reverse ETL allows business users to access data that they normally would only have access to in a BI tool in the platforms they use every day. As a result, business users can now use this data to personalize how they create ads, send emails, and communicate with customers.
Personalization was all the hype a few years ago and now, you rarely ever see an email come into your inbox without some sort of personalization in-place. Data teams using reverse ETL are able to pass down important customer information, such as location, customer lifetime value (CLV), tenure, and other fields, that can be used to create personalized emails, establish appropriate messaging, and segment email flows. All we can say: the possibilities for personalization powered by reverse ETL are endless.
Sophisticated paid marketing initiatives
At the end of the day, businesses want to serve the right ads to the right people (and at the right cost). A common use case for reverse ETL is for teams to use their customer data to create audiences in ad platforms to either serve specific audiences or create lookalikes. While ad platforms have gotten increasingly sophisticated with their algorithms to identify high-value audiences, it usually never hurts to try supplementing those audiences with your own data to create sophisticated audiences or lookalikes.
Self-service analytics culture
We hinted at it earlier, but reverse ETL efforts can be an effective way to promote a self-service analytics culture. When data teams put the data where business users need it, business users can confidently access it on their own, driving even faster insights and action. Instead of requesting a data pull from a data team member, they can find the data they need directly within the platform that they use. Reverse ETL allows business users to act on metrics that have already been built out and validated by data teams without creating ad-hoc requests.
“Real-time” data
It would be amiss if we didn’t mention reverse ETL and the notion of “real-time” data. While you can have the debate over the meaningfulness and true value-add of real-time data another time, reverse ETL can be a mechanism to bring data to end business platforms in a more “real-time” way.
Data teams can set up syncs in reverse ETL tools at higher cadences, allowing business users to have the data they need, faster. Obviously, there’s some cost-benefit analysis on how often you want to be loading data via ETL tools and hitting your data warehouse, but reverse ETL can help move data into external tools at a quicker cadence if deemed necessary.
All this to say: move with caution in the realm of “real-time”, understand your stakeholders’ wants and decision-making process for real-time data, and work towards a solution that’s both practical and impactful.
Reverse ETL tools
Reverse ETL tools typically establish the connection between your data warehouse and end business tools, offer an interface to create additional transformations or audiences, and support automation of downstream syncs. Below are some examples of tools that support reverse ETL pipelines.
| Tool | Description | Open source option? |
|---|---|---|
| Hightouch | A platform to sync data models and create custom audiences for downstream business platforms. | ❌ |
| Polytomic | A unified sync platform for syncing to and from data warehouses (ETL and Reverse ETL), databases, business apps, APIs, and spreadsheets. | ❌ |
| Census | Another reverse ETL tool that can sync data from your data warehouse to your go-to-market tools. | ❌ |
| Rudderstack | Also a CDP (customer data platform), Rudderstack additionally supports pushing down data and audience to external tools, such as ad platforms and email CRMs. | ✅ |
| Grouparoo | Grouparoo, part of Airbyte, is an open source framework to move data from data warehouses to different cloud-based tools. | ✅ |
Conclusion
Reverse ETL enables you to sync your transformed data stored in your data warehouse to external platforms often used by marketing, sales, and product teams. It allows you to leverage your data in a whole new way. Reverse ETL pipelines can support personalization efforts, sophisticated paid marketing initiatives, and ultimately offer new ways to leverage your data. In doing this, it creates a self-service analytics culture where stakeholders can receive the data they need in, in the places they need, in an automated way.
Further reading
If you’re interested learning more about reverse ETL and the impact it could have on your team, check out the following: