How to Create Near Real-time Models With Just dbt + SQL

Since this blog post was first published, many data platforms have added support for materialized views, which are a superior way to achieve the goals outlined here. We recommend them over the below approach.
Before I dive into how to create this, I have to say this. You probably don’t need this. I, along with my other Fishtown colleagues, have spent countless hours working with clients that ask for near-real-time streaming data. However, when we start digging into the project, it is often realized that the use case is not there. There are a variety of reasons why near real-time streaming is not a good fit. Two key ones are:
- The source data isn’t updating frequently enough.
- End users aren’t looking at the data often enough.
So when presented with a near-real-time modeling request, I (and you as well!) have to be cynical.
The right use case
Recently I was working on a JetBlue project and was presented with a legitimate use case: operational data. JetBlue’s Crewmembers need to make real-time decisions on when to close the door to a flight or rebook a flight. If you have ever been to an airport when there is a flight delay, you know how high the tension is in the room for airline employees to make the right decisions. They literally cannot do their jobs without real-time data.
If possible, the best thing to do is to query data as close to the source as possible. You don’t want to hit your production database unless you want to frighten and likely anger your DBA. Instead, the preferred approach is to replicate the source data to your analytics warehouse, which would provide a suitable environment for analytic queries. In JetBlue’s case, the data arrives in JSON blobs, which then need to be unnested, transformed, and joined before the data becomes useful for analysis. There was no way to just query from the source to get the information people required.
Tldr: If you need transformed, operational data to make in-the-moment decisions then you probably need real-time data.
What are our options?
1. Materialize everything as views
Since views are simply stored queries that do not store data, they are always up to date. This approach works until your transformations take more than 2+ minutes, which wouldn’t meet a “near real-time” SLA. When your data is small enough, this is the preferred approach, however it isn’t scalable.
2. Run dbt in micro-batches
Just don’t do it. Because dbt is primarily designed for batch-based data processing, you should not schedule your dbt jobs to run continuously. This can open the door to unforeseeable bugs.
3. Use Materialized Views
While the concept is very exciting, implementation still has some key limitations. They are expensive and cannot include some useful transformations. Check out this section in Snowflake’s documentation about their current limitations. Additionally, we have a office hours on this topic that I recommend checking out. Overall, we are excited to see how this develops.
4. Use a dedicated streaming stack
Tools like Materialize and Spark are great solutions to this problem. At the time of writing this post, these dbt adapters were not available and would have required a commitment to a new platform in this situation so they were not considered.
5. Use dbt in a clever way
By being thoughtful about how we define models, we can use dbt and the existing materializations to solve this problem. Lambda views are a simple and readily available solution that is tool agnostic and SQL based. This is what I implemented at JetBlue.
What are lambda views?
The idea of lambda views comes from lambda architecture. This Wikipedia page can explain much more in-depth but the core concept of this architecture is to take advantage of both batch and stream processing methods. This enables handling a lot of data in a very performant manner.
Taking that approach, a lambda view is essentially the union of a historical table and a current view. The model where the union takes place is the lambda view. Here is a diagram that might be helpful:
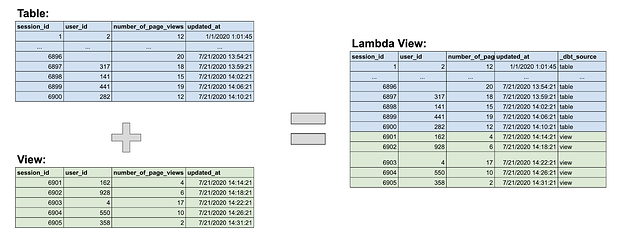
The lamba view can be queried for always up-to-date data, no matter how often you have run your dbt models. Since the majority of the records in the lambda view come directly from a table, it should be relatively fast to query. And since the most recent rows come from the view, transformations are run on a small subset of data which shouldn’t take long in the lambda view. This provides a performant and always up-to-date model.
The SQL in the lambda view is simple (just a union all), but there’s a bit of work to get to the unioned model. To better understand this, it is important to think about the flow of transformations as demonstrated below.
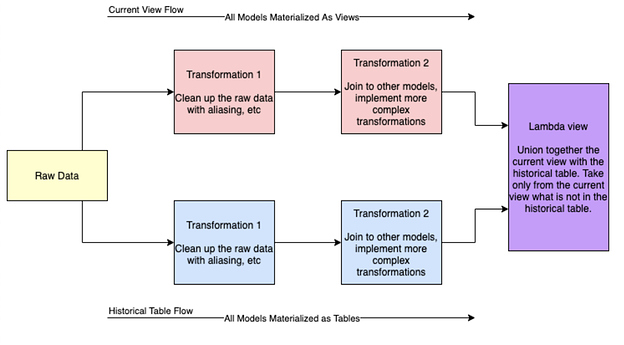
What is essentially happening is a series of parallel transformations from the raw data. Looking at the blue and red boxes that represent the creation of both the current view and historical table, you can see that they are the same transformations. The only key difference is that one flow is always using views as the materialization versus the other is materialized as tables. Often, those tables are incrementally built to improve performance.
The most basic version of the SQL looks like this:
with current_view as (
select * from {{ ref('current_view') }}
where max_collector_tstamp >= ‘{{ run_started_at }}’
),
historical_table as (
select * from {{ ref('historical_table') }}
where max_collector_tstamp < '{{ run_started_at }}'
),
unioned_tables as (
select * from current_view
union all
select * from historical_table
)
select * from unioned_tables
As you start to implement lambda views with more sources, creating a macro for the lambda view union is a great way to make things drier.
Key Concepts of a lambda view
Filters are key to making this performant
You need to filter often and intentionally on your current view flow. This is because there is usually a lot of data being transformed and you want to transform only what is necessary. There are two main places that filters should be considered.
- At the beginning of the current view flow: This is usually happening at Transformation 1. This filter takes into account how often the historical table is run. If it’s being run every hour, then I filter for only the last 2 hours of “current rows”. The overlap is assurance that if there are any issues with the job run, we don’t miss out on rows.
- At the unioned model: If you have late-arriving facts, you will want to include a primary key filter to assure that there are no fanouts.
As you start to create more lambda views, you will want to make the filter into a macro for drier code. Here is a sample macro for you to use:
{% macro lambda_filter(column_name) %}
{% set materialized = config.require('materialized') %}
{% set filter_time = var(lambda_timestamp, run_started_at) %}
{% if materialized == 'view' %}
where {{ column_name }} >= '{{ filter_time }}'
{% elif is_incremental() %}
where {{ column_name }} >= (select max({{ column_name }}) from {{ this }})
and {{ column_name }} < '{{ filter_time }}'
{% else %}
where {{ column_name }} < '{{ filter_time }}'
{% endif %}
{% endmacro %}
** Note for the macro above, the timestamp is var(lambda_timestamp, run_started_at). We want to default to the last time the historical models were run but allow for flexibility depending on the situation. It would be useful to note that we used run_started_at timestamp rather than current_timestamp() to avoid any situations where there is a job failure and the historical table hasn’t been updated for the last 5 hours.
Write idempotent models
As with every dbt model, be sure to keep this principle in mind as you start to create the models leading up to the union as well as the union itself.
Build the historical model intentionally
My dbt cloud jobs are set to run every hour, building all of the models in the historical table flow. All of the models leading up to the historical table are configured as an incremental model to improve performance.
Tradeoffs & Limitations
1. Duplicated logic
We are essentially creating duplicate models with the same logic, just different materializations. There are currently two approaches: 1) You can write the SQL in a macro and then have only one place to update this logic. This is great but creates complex folder organization and lowers model readability. 2) You can duplicate the SQL in both models but then there’s two places to update the logic in. This makes maintenance more error-prone.
2. Complex DAGs & Multi-step transformations
With every final model needing duplicate models, this makes DAGs significantly more complex. Add to that the need for more complex transformations, this approach may not scale up well due to the complexity.
3. Enforcing materializations
This approach is extremely dependent on the type of materializations. Requiring that models in the current view flow and their dependencies are all views can be challenging. Your project is more brittle because small changes can easily impact your data quality and how up-to-date it is.
Future implementations
All I can truly say is there’s more to come. Internally Jeremy and Claire have been working on if and how we should create a custom materialization to make this approach a lot cleaner. If interested, keep an eye out on our experimental features repo and contribute if you have thoughts!
Thank You
This post would not have materialized (lol) without the Fishtown Team working together.
Drew and I had a brainstorming session to discuss lambda architecture and the initial concept of lambda views. Sanajana and Jeremy were my rubber duckies as I started writing the SQL and conceptizing how things would work in code. Janessa and Claire also spent a lot of time helping me write this discourse post as I tried to form it between meetings. This is basically us at Fishtown.
I also want to give a special thanks to Ben from JetBlue who has been essential to this process from implementation to editing this post. My apologies for spelling JetBlue as Jetblue far too many times!