Your Essential dbt Project Checklist


If you’ve been using dbt for over a year, your project is out-of-date. This is natural.
New functionalities have been released. Warehouses change. Best practices are updated. Over the last year, I and others on the Fishtown Analytics (now dbt Labs!) team have conducted seven audits for clients who have been using dbt for a minimum of 2 months.
In every single audit, we found opportunities to:
- Improve performance
- Improve maintainability
- Make it easier for new people to get up-to-speed on the project
This post is the checklist I created to guide our internal work, and I’m sharing it here so you can use it to clean up your own dbt project. Think of this checklist like a Where's Waldo? book: you’ll still have to go out and find him, but with this in hand, you’ll at least know what you’re looking for.
✅ dbt_project.yml
- Project naming conventions
- What is the name of your project?
- Did you keep it as ‘my_new_project’ per the init project or renamed it to make sense?
- Our recommendation is to name it after your company such as ‘fishtown_analytics’.
- If you have multiple dbt projects, something like ‘fishtown_analytics_marketing’ might make more sense.
- What is the name of your project?
- Do you have unnecessary configurations like materialized: view?
- By default, dbt models are materialized as “views”. This removes the need to declare any models as views.
- If all of your models in a folder are tables, define the materialization on the dbt_project.yml file rather than on the model file. This removes clutter from the model file.
- Do you have a ton of placeholder comments from the init command?
- This creates unnecessary clutter.
- Do you use post-hooks to grant permissions to other transformers and BI users?
- If no, you should! This will ensure that any changes made will be accessible to your collaborators and be utilized on the BI layer.

- If no, you should! This will ensure that any changes made will be accessible to your collaborators and be utilized on the BI layer.
- Are you utilizing tags in your project?
- The majority of your project’s models should be untagged. Use tags for models and tests that fall out of the norm with how you want to interact with them. For example, tagging ‘nightly’ models makes sense, but also tagging all your non-nightly models as ‘hourly’ is unnecessary - you can simply exclude the nightly models!
- Check to see if a node selector is a good option here instead of tags.
- Are you tagging individual models in config blocks?
- You can use folder selectors in many cases to eliminate over tagging of every model in a folder.
- Are you using YAML selectors?
- These enable intricate, layered model selection and can eliminate complicated tagging mechanisms and improve the legibility of the project configuration
Useful links:
✅ Package Management
- How up to date are the versions of your dbt Packages?
- You can check this by looking at your packages.yml file and comparing it to the packages hub page.
- Do you have the dbt_utils package installed?
- This is by far our most popular and essential package. The package contains clever macros to improve your dbt Project. Once implemented, you have access to the macros (no need to copy them over to your project).
Useful links
✅ Code style
- Do you have a clearly defined code style?
- Are you following it strictly?
- Are you optimizing your SQL?
- Are you using window functions and aggregations?
Useful links
✅ Project structure
- If you are using dimensional modeling techniques, do you have staging and marts models?
- Do they use table prefixes like ‘fct_’ and ‘dim_’?
- Is the code modular? Is it one transformation per one model?
- Are you filtering as early as possible?
- One of the most common mistakes we have found is not filtering or transforming early enough. This causes multiple models downstream to have the same repeated logic (i.e., wet code) and makes updating business logic more cumbersome.
- Are the CTEs modular with one transformation per CTE?
- If you have macro files, are you naming them in a way that clearly represent the macro(s) contained in the file?
Useful links
✅ dbt
-
What version of dbt are you on?
- The further you get away from the latest release, the more likely you are to keep around old bugs and make updating that much harder.
-
What happens when you
dbt run?- What are your longest-running models?
- Is it time to reevaluate your modeling strategy?
- Should the model be incremental?
- If it’s already incremental, should you adjust your incremental strategy?
- How long does it take to run the entire dbt project?
- Does every model run? (This is not a joke.)
- If not, why?
- Do you have circular model references?
- What are your longest-running models?
-
Do you use sources?
- If so, do you use source freshness tests?
-
Do you use refs and sources for everything?
- Make sure nothing is querying off of raw tables, etc.

- Make sure nothing is querying off of raw tables, etc.
-
Do you regularly run
dbt testas part of your workflow and production jobs? -
Do you use Jinja & Macros for repeated code?
- If you do, is the balance met where it’s not being overused to the point code is not readable?
- Is your Jinja easy to read?
- Did you place all of your
setstatements at the top of the model files? - Did you format the code for Jinja-readability or just for the compiled SQL?
- Do you alter your whitespace?
- Example:
{{ this }}and not{{this}}
- Example:
- Did you place all of your
- Did you make complex macros as approachable as possible?
- Way to do this are providing argument names and in-line documentation using
{# <insert text> #}
- Way to do this are providing argument names and in-line documentation using
-
If you have incremental models, are they using unique keys and is_incremental() macro?
-
If you have tags, do they make sense? Do they get utilized?
Useful links
✅ Testing & Continuous Integration
- Do your models have tests?
- The ideal project has 100% test coverage on all of its models. While there are cases where this doesn’t make sense, our rule of thumb is models should have at least a not_null/unique test on the primary key.
- What are you testing for? Does it make sense?
- What are the assumptions you should be testing for?
- Think about your core business logic as well as your understanding of your sources.
- Are you using pull requests/other forms of version control?
- How easy is it to understand what the code change and intention behind the code change do?
- Do you have mandatory PR reviews before merging code to your dbt project or BI layer?
- Do you use a PR template?
Useful links
✅ Documentation
- Do you use documentation?
- Are there descriptions for each model?
- Are complex transformations and business logic explained in an easily accessible place?
- Are your stakeholders using your documentation?
- If not, why?
- Do you have a readme and regularly update it?
- How easy would it be to onboard someone to your project?
- If you have column-level descriptions, are you using doc blocks?
Useful Links
✅ dbt Cloud specifics
- What dbt version are the jobs?
- Are the majority of them inheriting from the environment to make upgrading easier?
- What do your jobs look like? Do they make sense?
- How are your dbt cloud projects organized?
- Do you have any unused projects?
- Have you chosen the most appropriate job for your account level documentation?
- Are the number of runs syncing up with how often your raw data updates and are viewed?
- If your data isn’t updating as often as the runs are happening, this is just not doing anything.
- Do you have a full refresh of the production data?
- Do you run tests on a periodic basis?
- What are the longest-running jobs?
- Do you have a Continuous Integration job? (Github only)
Are you using the IDE and if so, how well?
- We found that the IDE has assisted in alleviating issues of maintaining the upgraded dbt version.
- Does dbt cloud have its own user in their warehouse? What is the default warehouse/role?
- Are you getting notifications for failed jobs? Have you set up the slack notifications?
Useful links
✅ DAG Auditing
Note: diagrams in this section show what NOT to do!
- Does your DAG have any common modeling pitfalls?
-
Are there any direct joins from sources into an intermediate model?
-
All sources should have a corresponding staging model to clean and standardize the data structure. They should not look like the image below.
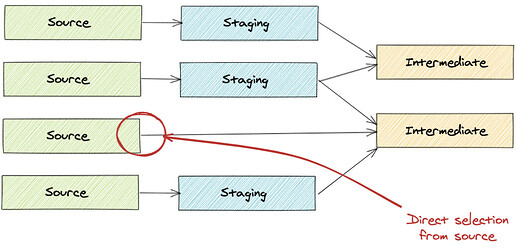
-
-
Do sources join directly together?
-
All sources should have a corresponding staging model to clean and standardize the data structure. They should not look like the image below.
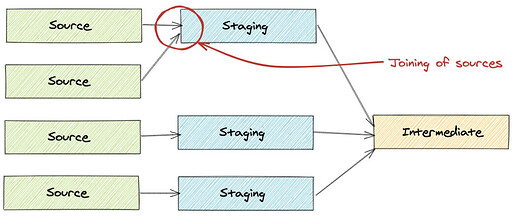
-
-
Are there any rejoining of upstream concepts?
- This may indicate:
-
a model may need to be expanded so all the necessary data is available downstream
-
a new intermediate model is necessary to join the concepts for use in both places
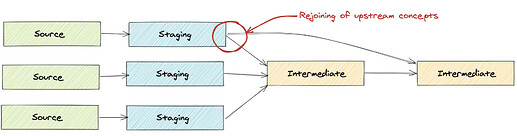
-
- This may indicate:
-
Are there any “bending connections”?
-
Are models in the same layer dependent on each other?
-
This may indicate a change in naming is necessary, or the model should reference further upstream models
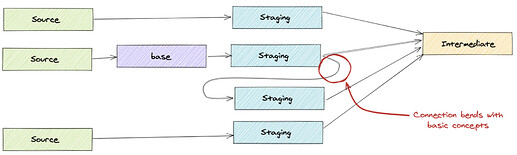
-
-
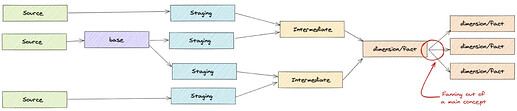
Are there model fan outs of intermediate/dimension/fact models?
-
This might indicate some transformations should move to the BI layer, or transformations should be moved upstream
-
Your dbt project needs a defined end point!
[
-
-
Is there repeated logic found in multiple models?
- This indicates an opportunity to move logic into upstream models or create specific intermediate models to make that logic reusable
- One common place to look for this is complex join logic. For example, if you’re checking multiple fields for certain specific values in a join, these can likely be condensed into a single field in an upstream model to create a clean, simple join.
-
Thanks to Christine Berger for her DAG diagrams!
Useful links
- How we structure our dbt Project
- Coalesce DAG Audit Talk
- Modular Data Modeling Technique
- Understanding Threads
This is a quick overview of things to think about in your project. We’ll keep this post updated as we continue to refine our best practices! Happy modeling!