No babysitting, not today

We recently released dbt Wizard, a CLI for doing agentic data work on dbt. This is a harness specifically built for data work and as such I was excited to spend an afternoon running dbt Wizard across a personal project with about 100 models or so that I've been maintaining for a while. You can use this project to see firsthand some of the differentiators for Wizard, particularly how the validation loop works.
Data projects are never done and I had a few tasks I've been putting off:
- Migrating from MotherDuck to Iceberg + BigQuery
- Upgrading dbt Core to dbt Fusion
- Migrating from dbt Core to dbt platform
- Building out a semantic layer
These are a good mix of pretty standard data work (have you done your annual migration yet?) and some dbt specific tasks. A good informal eval for the fundamental question for any dev tool: Does it work?
I was pleasantly surprised with my experience in that I didn't have to babysit Wizard or build any additional workflows on top of it. Because it has a native understanding of what a dbt project is, and its ability to set up validation subagents that match the task made it easy for me to just pop in when needed and I didn't have to babysit the whole process and I accomplished all of my objectives.
The repo is public, so you can read the prs that Wizard authored:
- Migrate from MotherDuck to BigQuery + Apache Iceberg
- Prepare dbt Platform and Fusion orchestration
- Fix Semantic Layer for Fusion metric discovery
Project background
The project is an economic data platform. The Federal Reserve, Bureau of Labor Statistics, Historical stock, ETF commodity prices, and Treasury data come in through Dagster assets, get transformed by dbt, and feed a set of analysis agents. DuckDB and MotherDuck worked fantastically, but I wanted to test out the developer ergonomics and cost of Iceberg, and the dbt Fusion engine.
The primary interface that I use to consume this data is via a Claude plugin where I ask questions about market state, where we are in the economic cycle, running backtests, that type of thing. It helps me test new investment and trade ideas and going back and forth with an AI is pretty ergonomic for this type of thing. I had some issues with data quality in the past so improving accuracy and repeatability is important. I also had Wizard build out the initial Semantic Layer and metrics.
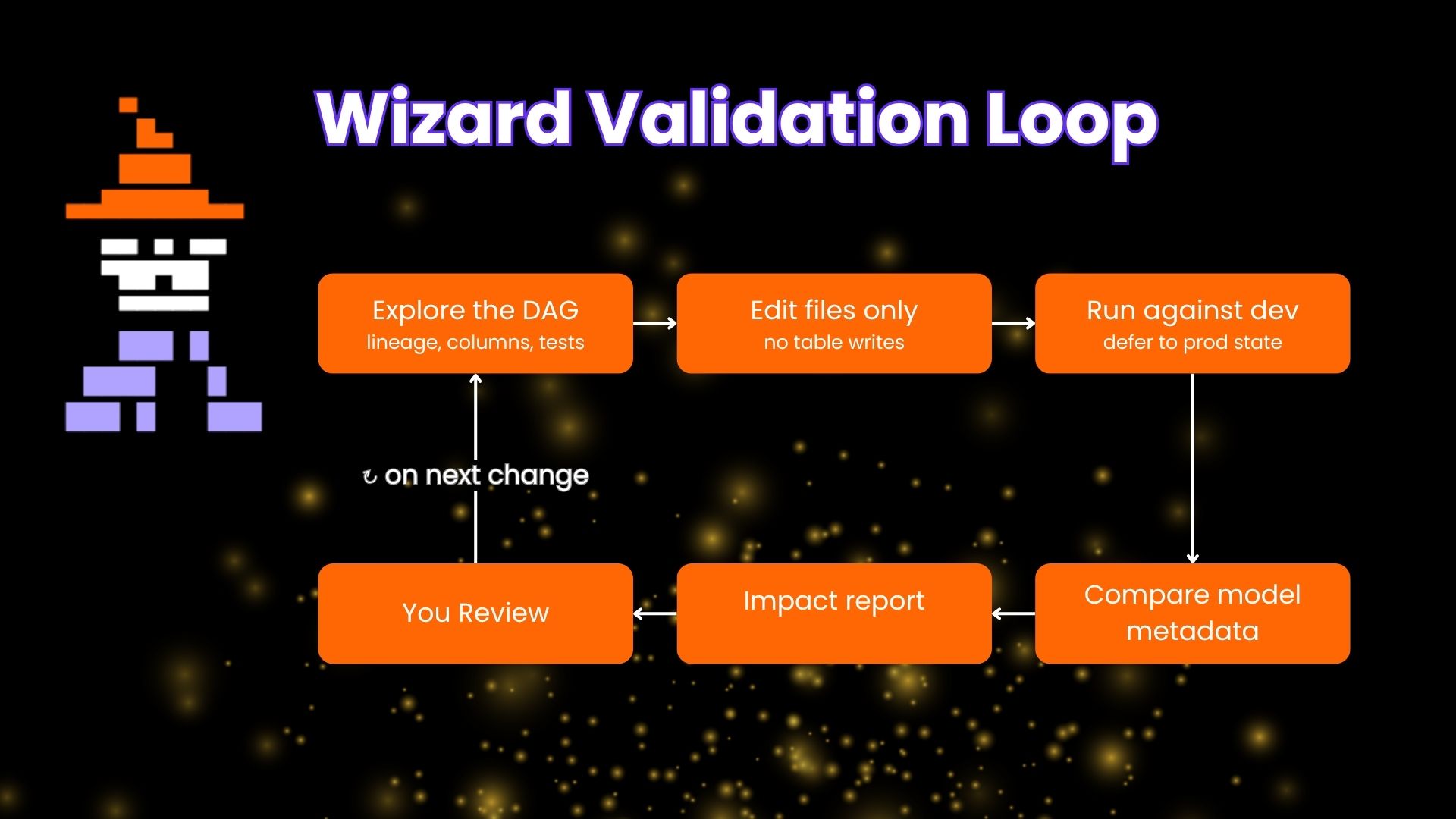
The Validation loop in practice
Wizard has this built-in validation loop that starts with the intended change, implements the most reasonable version, checks to see if it works in the project, if validation fails or exposes a mismatch, Wizard adjusts the implementation.
A common metric that I look at when thinking about the financial market is volatility or price variance. Being able to normalize across nominal prices is necessary so you can do a true apples to apples comparison. The calculation works like this:
V = σ_1yr / P_current
where:
σ_1yr = trailing one-year standard deviation of the price
P_current = the latest close
Take the one-year standard deviation of a price, divide by the current price, and you get a dimensionless volatility proxy you can compare across assets at wildly different price levels.
- name: annualized_volatility_ratio
type: ratio
type_params:
numerator:
name: price_volatility_proxy
denominator:
name: max_close_price
This was Wizard’s first attempt, pretty simple. It failed during the validation loop because it had two modeling problems:
Max_close_pricewas not quite the expression I wanted, current\last_price was what I needed, not the max close over a current window.- It depended on cross-metric references in metrics.yml, which became fragile once Wizard migrated metrics inline to be in support of fusion.
For validation Wizard had to work within the following constraints:
- Fusion needed to discover metrics colocated with model YAML.
- dbt Core/Dagster needed to parse the project without choking on newer semantic syntax. (I ended up fixing this later to be Fusion across the board but it was a fun challenge to see Wizard deal with)
- CI needed a stable project parse/build path.
- dbt Platform needed deployed artifacts that the hosted Semantic Layer could actually expose.
Wizard tried again with an older MetricFlow-style shape. Which was suboptimal in that it worked for one parser but didn't work for another.
Better for one parser, worse for the other. It flipped which side failed, which is the kind of result that eats an afternoon when you do it by hand.
The version that shipped is the least clever of the three but it worked.
- name: annualized_volatility_ratio
label: Annualized Volatility Ratio
description: Average ratio of 1-year price StdDev to close price, a dimensionless proxy for annualized volatility. Higher means more volatile relative to price level.
type: simple
agg: average
expr: std_diff_1yr / nullif(current_price, 0)
The ratio logic moved into the expr, the nullif kills the divide-by-zero, and it parses under Fusion, parses under dbt Core, and passes the project CI. Having Wizard do the validation loop to understand the finer points in the differences between dbt Core and Fusion saved me a ton of time.
For this process, I didn't have to look up any documentation and only had to go back and forth with Wizard a few times, mostly for my understanding. This was a success for me since I now have a simple metric, that matches the expected formula, and has both parser compatibility and a hosted semantic layer deployment path. I also only had to see on diff, which was the final one, the dead ends and iterations happened off screen so I only needed to be tapped in when necessary.
Why it could run unattended
Three things made that work, some of them can be replicated with other harnesses using skills, MCPs, hooks and other automation but these came out of the box.
It knew the graph before it started. Wizard has a native metadata engine, a structured index of lineage, models, tests, and metric definitions, built before the first prompt. When it wrote std_diff_1yr and current_price into that expr, it didn't have to grep through the sql files to find the right name it was able to quickly know what field was the right ones.
Validation was the default. I never said "check that it compiles." The loop runs on write operations whether you ask or not. You can turn this feature off if it isn't interesting to you.
It stayed in its sandbox. The task was building out an initial set of metrics in the markets domain. It didn't wander off to refactor unrelated models or rewrite my Dagster assets. It scoped the change, iterated inside that scope, and surfaced a diff for review. Nothing persisted without my approval. This tight scope is what makes "look away and come back" a safe move instead of having a tech debt super spreader event.
The proof I wanted
A green compile is not proof a Semantic Layer change works. It tells you the YAML is shaped right, not that a metric is discoverable and queryable against your real warehouse. So after the PR merged and the dbt platform jobs ran, I checked the hosted layer directly: dialect BIGQUERY, 43 metrics discovered, query status SUCCESSFUL. Then I ran an actual metric query through the dbt MCP and got real numbers back from BigQuery.
But the biggest proof for me is that I was able to give Wizard a defined set of analytics tasks before a string of meetings and it just went through and completed them without any major interventions on my end. The best part was at the end of it everything worked and during those meetings I was able to be present and contribute without being tempted to make sure my agent wasn't going off the rails. Maybe the real evals were the friends we made along the way.
Other things it did well
A few shorter wins from the same stretch of work:
- It refused to chase a misleading error. A local command threw a Snowflake auth error in a BigQuery project. Wizard separated the hosted environment (correctly BigQuery) from a stale Snowflake credential path on my laptop. That reframed the fix from "production is broken" to "your local creds are stale," which is the difference between an hour and a day.
- It knew "merged" and "available" are different states. A merged PR doesn't mean the Semantic Layer refreshed. Wizard traced the gap to dbt platform job execution, ran the deploy jobs, then confirmed the metrics were live.
- It colocated the definitions. The metrics started scattered across standalone files. Wizard moved them into model-owned
schema.yml, so each metric sits next to the columns it measures. The Semantic Layer stopped being a metadata island. - It made a pragmatic cut. Some saved queries were brittle against the migrated metrics. Rather than block the change, it pulled them out, shipped stable metric discovery first, and left them as follow-up. I'd have fought them for an hour. Cutting was right.
Try it
The repo is public if you are curious about the actual metrics and the merged PRs:. Install the Wizard CLI and point it at a project that runs Fusion or dbt Core:
curl -fsSL https://public.cdn.getdbt.com/dbt-wizard/install/install-wizard.sh | sh
The Wizard docs cover setup, and how it works goes deeper on the validation loop. If you try it on a migration of your own, come tell me in #dbt-wizard in the dbt Community Slack.