Airflow and dbt
Introduction
Many organizations already use Airflow to orchestrate their data workflows. dbt works great with Airflow, letting you execute your dbt code in dbt while keeping orchestration duties with Airflow. This ensures your project's metadata (important for tools like Catalog) is available and up-to-date, while still enabling you to use Airflow for general tasks such as:
- Scheduling other processes outside of dbt runs
- Ensuring that a dbt job kicks off before or after another process outside of dbt
- Triggering a dbt job only after another has completed
In this guide, you'll learn how to:
- Create a working local Airflow environment
- Invoke a dbt job with Airflow
- Reuse tested and trusted Airflow code for your specific use cases
You’ll also gain a better understanding of how this will:
- Reduce the cognitive load when building and maintaining pipelines
- Avoid dependency hell (think:
pip installconflicts) - Define clearer handoff of workflows between data engineers and analytics engineers
Prerequisites
- dbt platform Enterprise or Enterprise+ account (with admin access) in order to create a service token. Permissions for service tokens can be found here.
- Service account token if you have Developer license (with admins access)). Permissions for service tokens can be found here and here.
- Personal access token (PAT) if you have developer, IT, or Read-only license.
- A free Docker account in order to sign in to Docker Desktop, which will be installed in the initial setup.
- A local digital scratchpad for temporarily copy-pasting API keys and URLs
🙌 Let’s get started! 🙌
Install the Astro CLI
Astro is a managed software service that includes key features for teams working with Airflow. In order to use Astro, we’ll install the Astro CLI, which will give us access to useful commands for working with Airflow locally. You can read more about Astro here.
In this example, we’re using Homebrew to install Astro CLI. Follow the instructions to install the Astro CLI for your own operating system here.
brew install astro
Install and start Docker Desktop
Docker allows us to spin up an environment with all the apps and dependencies we need for this guide.
Follow the instructions here to install Docker desktop for your own operating system. Once Docker is installed, ensure you have it up and running for the next steps.
Clone the airflow-dbt-cloud repository
Open your terminal and clone the airflow-dbt-cloud repository. This contains example Airflow DAGs that you’ll use to orchestrate your dbt job. Once cloned, navigate into the airflow-dbt-cloud project.
git clone https://github.com/dbt-labs/airflow-dbt-cloud.git
cd airflow-dbt-cloud
For more information about cloning GitHub repositories, refer to "Cloning a repository" in the GitHub documentation.
Start the Docker container
-
From the
airflow-dbt-clouddirectory you cloned and opened in the prior step, run the following command to start your local Airflow deployment:astro dev startWhen this finishes, you should see a message similar to the following:
Airflow is starting up! This might take a few minutes…
Project is running! All components are now available.
Airflow Webserver: http://localhost:8080
Postgres Database: localhost:5432/postgres
The default Airflow UI credentials are: admin:admin
The default Postgres DB credentials are: postgres:postgres -
Open the Airflow interface. Launch your web browser and navigate to the address for the Airflow Webserver from your output above (for us,
http://localhost:8080).This will take you to your local instance of Airflow. You’ll need to log in with the default credentials:
- Username: admin
- Password: admin
Create a dbt service token
Create a service token with Job Admin privileges from within dbt. Ensure that you save a copy of the token, as you won’t be able to access this later.
As an alternative, you can create a PAT if you have a Developer, IT, or Read-only license.
Create a dbt job
Create a job in your dbt account, paying special attention to the information in the bullets below.
- Configure the job with the full commands that you want to include when this job kicks off. This sample code has Airflow triggering the dbt job and all of its commands, instead of explicitly identifying individual models to run from inside of Airflow.
- Ensure that the schedule is turned off since we’ll be using Airflow to kick things off.
- Once you hit
saveon the job, make sure you copy the URL and save it for referencing later. The url will look similar to this:
https://YOUR_ACCESS_URL/#/accounts/{account_id}/projects/{project_id}/jobs/{job_id}/
Connect dbt to Airflow
Now you have all the working pieces to get up and running with Airflow + dbt. It's time to set up a connection and run a DAG in Airflow that kicks off a dbt job.
-
From the Airflow interface, navigate to Admin and click on Connections
-
Click on the
+sign to add a new connection, then click on the drop down to search for the dbt Connection Type.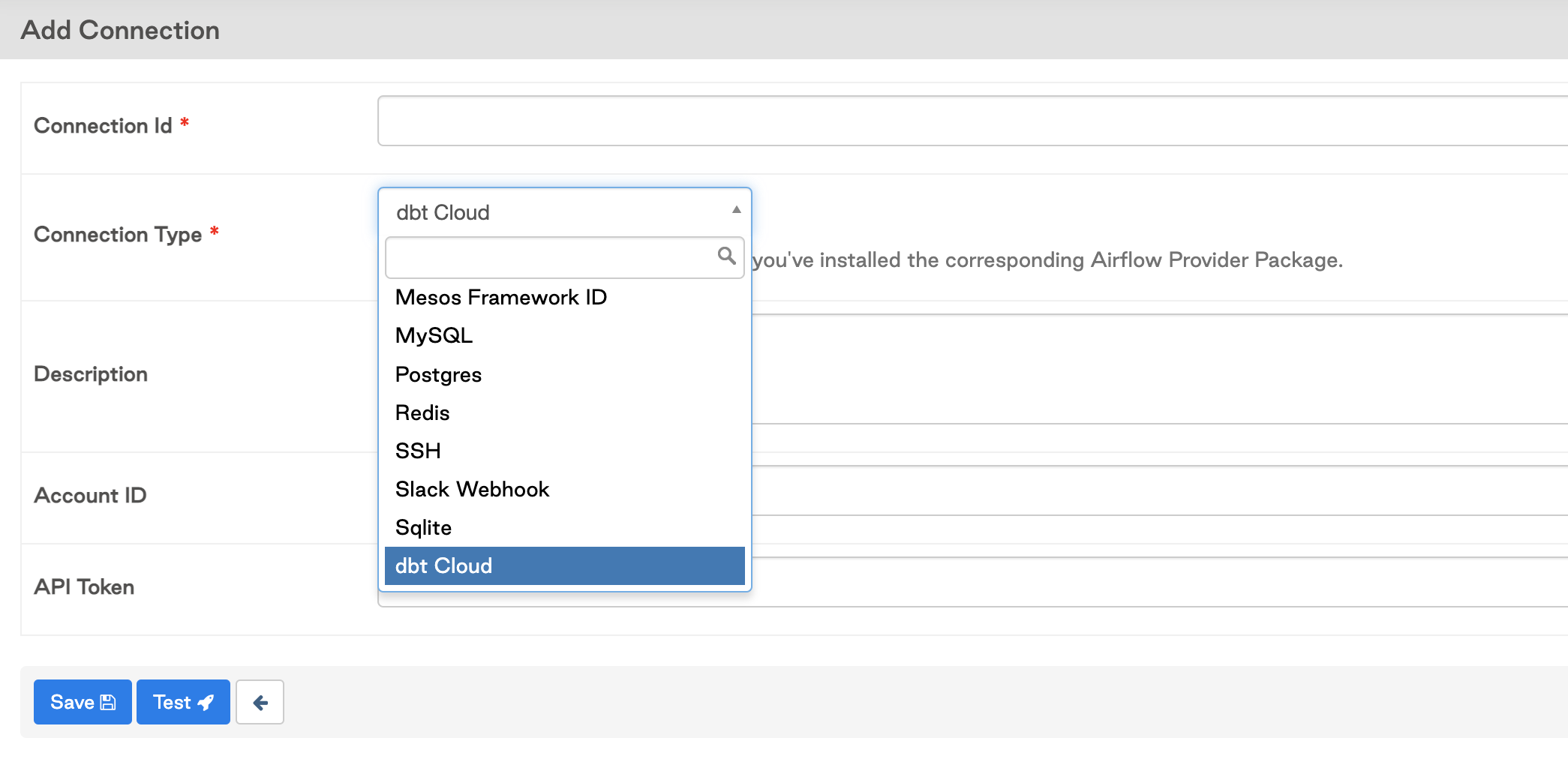
-
Add in your connection details and your default dbt account id. This is found in your dbt URL after the accounts route section (
/accounts/{YOUR_ACCOUNT_ID}), for example the account with id 16173 would see this in their URL:https://YOUR_ACCESS_URL/#/accounts/16173/projects/36467/jobs/65767/
Update the placeholders in the sample code
Add your account_id and job_id to the python file run_dbt_cloud_job.py.
Both IDs are included inside of the dbt job URL as shown in the following snippets:
# For the dbt Job URL https://YOUR_ACCESS_URL/#/accounts/16173/projects/36467/jobs/65767/
# The account_id is 16173 and the job_id is 65767
# Update lines 34 and 35
ACCOUNT_ID = "16173"
JOB_ID = "65767"
Run the Airflow DAG
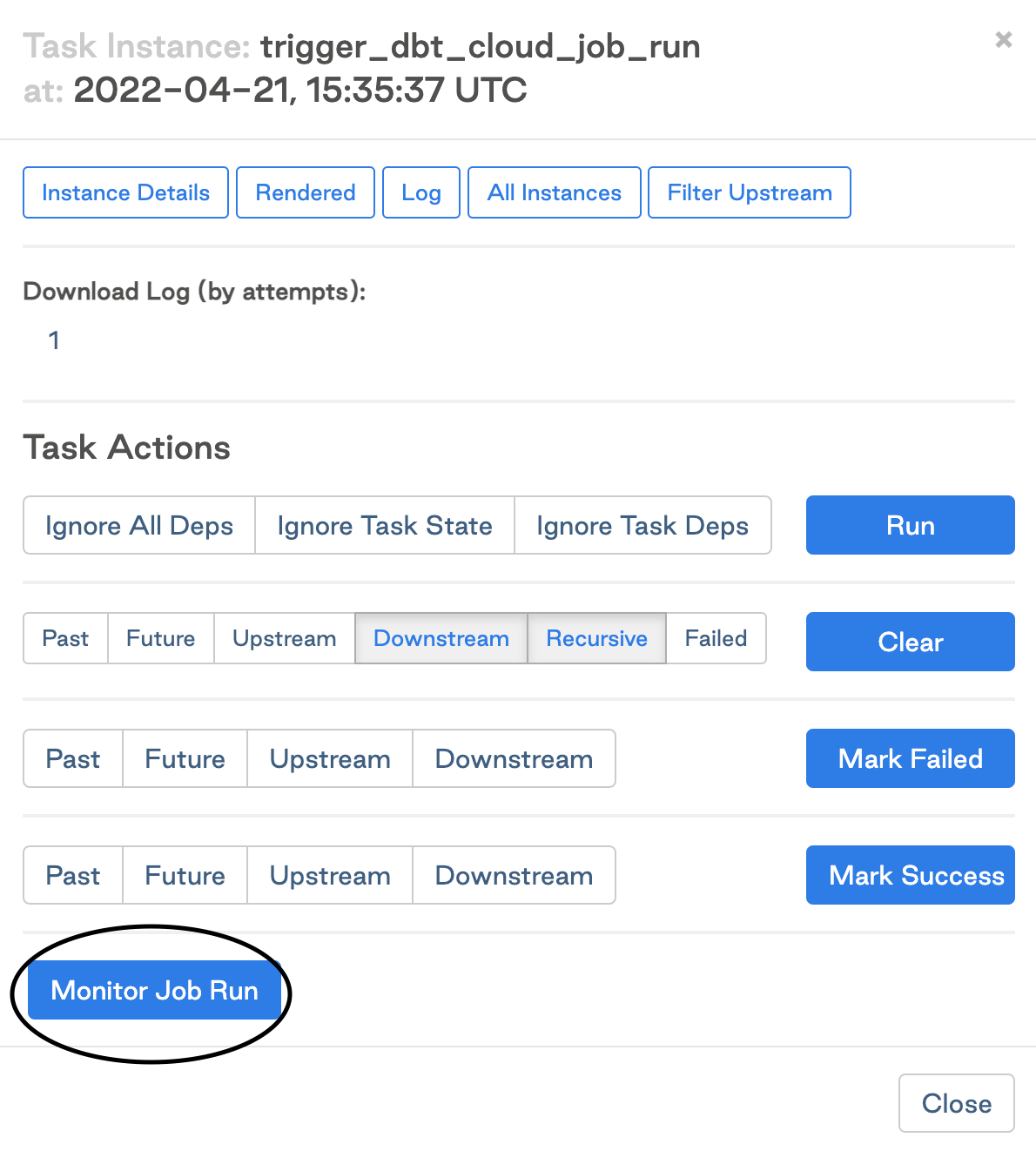
Turn on the DAG and trigger it to run. Verify the job succeeded after running.
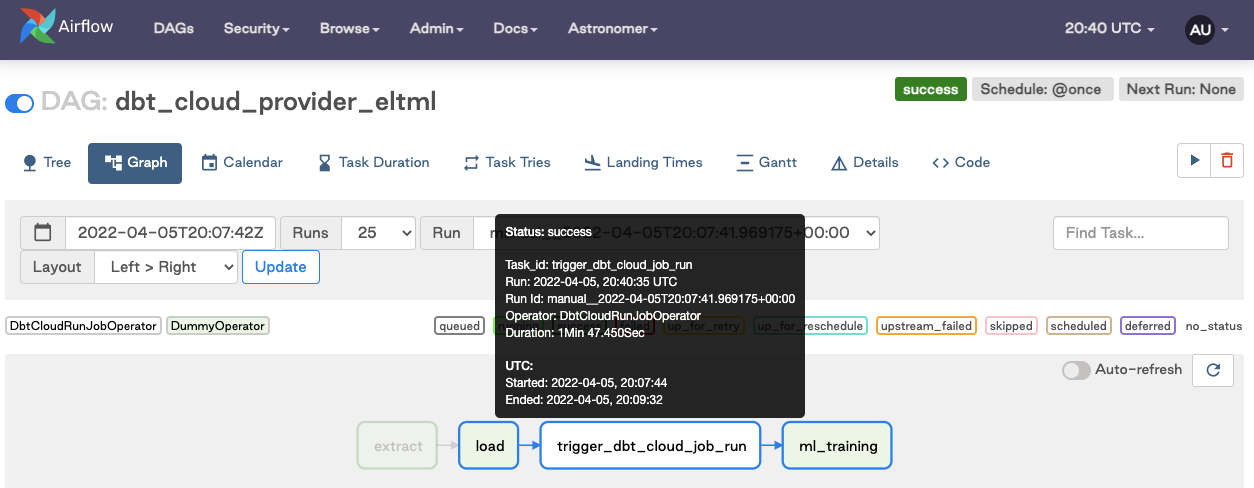
Click Monitor Job Run to open the run details in dbt.
Cleaning up
At the end of this guide, make sure you shut down your docker container. When you’re done using Airflow, use the following command to stop the container:
$ astrocloud dev stop
[+] Running 3/3
⠿ Container airflow-dbt-cloud_e3fe3c-webserver-1 Stopped 7.5s
⠿ Container airflow-dbt-cloud_e3fe3c-scheduler-1 Stopped 3.3s
⠿ Container airflow-dbt-cloud_e3fe3c-postgres-1 Stopped 0.3s
To verify that the deployment has stopped, use the following command:
astrocloud dev ps
This should give you an output like this:
Name State Ports
airflow-dbt-cloud_e3fe3c-webserver-1 exited
airflow-dbt-cloud_e3fe3c-scheduler-1 exited
airflow-dbt-cloud_e3fe3c-postgres-1 exited
Frequently asked questions
How can we run specific subsections of the dbt DAG in Airflow?
Because the Airflow DAG references dbt jobs, your analytics engineers can take responsibility for configuring the jobs in dbt.
For example, to run some models hourly and others daily, there will be jobs like Hourly Run or Daily Run using the commands dbt run --select tag:hourly and dbt run --select tag:daily respectively. Once configured in dbt, these can be added as steps in an Airflow DAG as shown in this guide. Refer to our full node selection syntax docs here.
How can I re-run models from the point of failure?
You can trigger re-run from point of failure with the rerun API endpoint. See the docs on retrying jobs for more information.
Should Airflow run one big dbt job or many dbt jobs?
dbt jobs are most effective when a build command contains as many models at once as is practical. This is because dbt manages the dependencies between models and coordinates running them in order, which ensures that your jobs can run in a highly parallelized fashion. It also streamlines the debugging process when a model fails and enables re-run from point of failure.
As an explicit example, it's not recommended to have a dbt job for every single node in your DAG. Try combining your steps according to desired run frequency, or grouping by department (finance, marketing, customer success...) instead.
We want to kick off our dbt jobs after our ingestion tool (such as Fivetran) / data pipelines are done loading data. Any best practices around that?
Astronomer's DAG registry has a sample workflow combining Fivetran, dbt and Census here.
How do you set up a CI/CD workflow with Airflow?
Check out these two resources for accomplishing your own CI/CD pipeline:
Can dbt dynamically create tasks in the DAG like Airflow can?
As discussed above, we prefer to keep jobs bundled together and containing as many nodes as are necessary. If you must run nodes one at a time for some reason, then review this article for some pointers.
Can you trigger notifications if a dbt job fails with Airflow?
Yes, either through Airflow's email/slack functionality, or dbt's notifications, which support email and Slack notifications. You could also create a webhook.
How should I plan my dbt + Airflow implementation?
Check out this recording of a dbt meetup for some tips.
Was this page helpful?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.