Build, test, document, and promote adapters
This guide is for creating adapters for the Python-based dbt Core v1. For adapter creation on the Rust-based dbt Core v2.0, check out our new guide
Introduction
Adapters are an essential component of dbt. At their most basic level, they are how dbt connects with the various supported data platforms. At a higher-level, dbt Core v1.x adapters strive to give analytics engineers more transferrable skills as well as standardize how analytics projects are structured. Gone are the days where you have to learn a new language or flavor of SQL when you move to a new job that has a different data platform. That is the power of adapters in dbt Core v1.x.
Navigating and developing around the nuances of different databases can be daunting, but you are not alone. Visit #adapter-ecosystem Slack channel for additional help beyond the documentation.
All databases are not the same
There's a tremendous amount of work that goes into creating a database. Here is a high-level list of typical database layers (from the outermost layer moving inwards):
- SQL API
- Client Library / Driver
- Server Connection Manager
- Query parser
- Query optimizer
- Runtime
- Storage Access Layer
- Storage
There's a lot more there than just SQL as a language. Databases (and data warehouses) are so popular because you can abstract away a great deal of the complexity from your brain to the database itself. This enables you to focus more on the data.
dbt allows for further abstraction and standardization of the outermost layers of a database (SQL API, client library, connection manager) into a framework that both:
- Opens database technology to less technical users (a large swath of a DBA's role has been automated, similar to how the vast majority of folks with websites today no longer have to be "webmasters").
- Enables more meaningful conversations about how data warehousing should be done.
This is where dbt adapters become critical.
What needs to be adapted?
dbt adapters are responsible for adapting dbt's standard functionality to a particular database. Our prototypical database and adapter are PostgreSQL and dbt-postgres, and most of our adapters are somewhat based on the functionality described in dbt-postgres.
Connecting dbt to a new database will require a new adapter to be built or an existing adapter to be extended.
The outermost layers of a database map roughly to the areas in which the dbt adapter framework encapsulates inter-database differences.
SQL API
Even amongst ANSI-compliant databases, there are differences in the SQL grammar. Here are some categories and examples of SQL statements that can be constructed differently:
| Loading table... |
Python Client Library & Connection Manager
The other big category of inter-database differences comes with how the client connects to the database and executes queries against the connection. To integrate with dbt, a data platform must have a pre-existing python client library or support ODBC, using a generic python library like pyodbc.
| Loading table... |
How dbt encapsulates and abstracts these differences
Differences between databases are encoded into discrete areas:
| Loading table... |
Python classes
These classes implement all the methods responsible for:
- Connecting to a database and issuing queries.
- Providing dbt with database-specific configuration information.
| Loading table... |
Macros
A set of macros responsible for generating SQL that is compliant with the target database.
Materializations
A set of materializations and their corresponding helper macros defined in dbt using Jinja and SQL. They codify for dbt how model files should be persisted into the database.
Adapter Architecture
Below is a flow diagram illustrating how a dbt run command works with the dbt-postgres adapter. It shows the relationship between dbt-core, dbt-adapters, and individual adapters.
 Diagram of adapter architecture
Diagram of adapter architecturePrerequisites
It is very important that you have the right skills, and understand the level of difficulty required to make an adapter for your data platform.
The more you can answer Yes to the below questions, the easier your adapter development (and user-) experience will be. See the New Adapter Information Sheet wiki for even more specific questions.
Training
- The developer (and any product managers) ideally will have substantial experience as an end-user of dbt. If not, it is highly advised that you at least take the dbt Fundamentals and Advanced Materializations course.
Database
- Does the database complete transactions fast enough for interactive development?
- Can you execute SQL against the data platform?
- Is there a concept of schemas?
- Does the data platform support ANSI SQL, or at least a subset?
Driver / Connection Library
- Is there a Python-based driver for interacting with the database that is db API 2.0 compliant (e.g. Psycopg2 for Postgres, pyodbc for SQL Server)
- Does it support: prepared statements, multiple statements, or single sign on token authorization to the data platform?
Open source software
- Does your organization have an established process for publishing open source software?
It is easiest to build an adapter for dbt when the following the data warehouse/platform in question has:
- a conventional ANSI-SQL interface (or as close to it as possible),
- a mature connection library/SDK that uses ODBC or Python DB 2 API, and
- a way to enable developers to iterate rapidly with both quick reads and writes
Maintaining your new adapter
When your adapter becomes more popular, and people start using it, you may quickly become the maintainer of an increasingly popular open source project. With this new role, comes some unexpected responsibilities that not only include code maintenance, but also working with a community of users and contributors. To help people understand what to expect of your project, you should communicate your intentions early and often in your adapter documentation or README. Answer questions like, Is this experimental work that people should use at their own risk? Or is this production-grade code that you're committed to maintaining into the future?
Keeping the code compatible with dbt Core v1.x
An adapter is compatible with dbt Core v1.x if it has correctly implemented the interface defined in dbt-adapters and is tested by dbt-tests-adapters. Prior to dbt Core v1.x version 1.8, this interface was contained in dbt-core.
New minor version releases of dbt-adapters may include changes to the Python interface for adapter plugins, as well as new or updated test cases. The maintainers of dbt-adapters will clearly communicate these changes in documentation and release notes, and they will aim for backwards compatibility whenever possible.
Patch releases of dbt-adapters will not include breaking changes or new features to adapter-facing code.
Versioning and releasing your adapter
dbt Labs strongly recommends you to adopt the following approach when versioning and releasing your plugin.
- Declare major version compatibility with
dbt-adaptersand only set a boundary on the minor version if there is some known reason. - Do not import or rely on code from
dbt-core. - Aim to release a new minor version of your plugin as you add substantial new features. Typically, this will be triggered by adding support for new features released in
dbt-adaptersor by changes to the data platform itself. - While your plugin is new and you're iterating on features, aim to offer backwards compatibility and deprecation notices for at least one minor version. As your plugin matures, aim to leave backwards compatibility and deprecation notices in place until the next major version (dbt Core v2.0).
- Release patch versions of your plugins whenever needed. These patch releases should only contain fixes.
Prior to dbt Core v1.x version 1.8, we recommended that the minor version of your plugin should match the minor version in dbt-core (for example, 1.1.x).
Build a new adapter
This step will walk you through the first creating the necessary adapter classes and macros, and provide some resources to help you validate that your new adapter is working correctly. Make sure you've familiarized yourself with the previous steps in this guide.
Once the adapter is passing most of the functional tests in the previous "Testing a new adapter" step, please let the community know that is available to use by adding the adapter to the "Supported Data Platforms" page by following the steps given in "Documenting your adapter.
For any questions you may have, don't hesitate to ask in the #adapter-ecosystem Slack channel. The community is very helpful and likely has experienced a similar issue as you.
Scaffolding a new adapter
To create a new adapter plugin from scratch, you can use the dbt-database-adapter-scaffold to trigger an interactive session which will generate a scaffolding for you to build upon.
Example usage:
$ cookiecutter gh:dbt-labs/dbt-database-adapter-scaffold
The generated boilerplate starting project will include a basic adapter plugin file structure, examples of macros, high level method descriptions, etc.
One of the most important choices you will make during the cookiecutter generation will revolve around the field for is_sql_adapter which is a boolean used to correctly apply imports for either a SQLAdapter or BaseAdapter. Knowing which you will need requires a deeper knowledge of your selected database but a few good guides for the choice are.
- Does your database have a complete SQL API? Can it perform tasks using SQL such as creating schemas, dropping schemas, querying an
information_schemafor metadata calls? If so, it is more likely to be a SQLAdapter where you setis_sql_adaptertoTrue. - Most adapters do fall under SQL adapters which is why we chose it as the default
Truevalue. - It is very possible to build out a fully functional
BaseAdapter. This will require a little more ground work as it doesn't come with some prebuilt methods theSQLAdapterclass provides. Seedbt-bigqueryas a good guide.
Implementation details
Regardless if you decide to use the cookiecutter template or manually create the plugin, this section will go over each method that is required to be implemented. The following table provides a high-level overview of the classes, methods, and macros you may have to define for your data platform.
| Loading table... |
Editing setup.py
Edit the file at myadapter/setup.py and fill in the missing information.
You can skip this step if you passed the arguments for email, url, author, and dependencies to the cookiecutter template script. If you plan on having nested macro folder structures, you may need to add entries to package_data so your macro source files get installed.
Editing the connection manager
Edit the connection manager at myadapter/dbt/adapters/myadapter/connections.py. This file is defined in the sections below.
The Credentials class
The credentials class defines all of the database-specific credentials (e.g. username and password) that users will need in the connection profile for your new adapter. Each credentials contract should subclass dbt.adapters.base.Credentials, and be implemented as a python dataclass.
Note that the base class includes required database and schema fields, as dbt uses those values internally.
For example, if your adapter requires a host, integer port, username string, and password string, but host is the only required field, you'd add definitions for those new properties to the class as types, like this:
from dataclasses import dataclass
from typing import Optional
from dbt.adapters.base import Credentials
@dataclass
class MyAdapterCredentials(Credentials):
host: str
port: int = 1337
username: Optional[str] = None
password: Optional[str] = None
@property
def type(self):
return 'myadapter'
@property
def unique_field(self):
"""
Hashed and included in anonymous telemetry to track adapter adoption.
Pick a field that can uniquely identify one team/organization building with this adapter
"""
return self.host
def _connection_keys(self):
"""
List of keys to display in the `dbt debug` output.
"""
return ('host', 'port', 'database', 'username')
There are a few things you can do to make it easier for users when connecting to your database:
- Be sure to implement the Credentials'
_connection_keysmethod shown above. This method will return the keys that should be displayed in the output of thedbt debugcommand. As a general rule, it's good to return all the arguments used in connecting to the actual database except the password (even optional arguments). - Create a
profile_template.ymlto enable configuration prompts for a brand-new user setting up a connection profile via thedbt initcommand. You will find more details in the following steps. - You may also want to define an
ALIASESmapping on your Credentials class to include any config names you want users to be able to use in place of 'database' or 'schema'. For example if everyone using the MyAdapter database calls their databases "collections", you might do:
@dataclass
class MyAdapterCredentials(Credentials):
host: str
port: int = 1337
username: Optional[str] = None
password: Optional[str] = None
ALIASES = {
'collection': 'database',
}
Then users can use collection OR database in their profiles.yml, dbt_project.yml, or config() calls to set the database.
ConnectionManager class methods
Once credentials are configured, you'll need to implement some connection-oriented methods. They are enumerated in the SQLConnectionManager docstring, but an overview will also be provided here.
Methods to implement:
openget_responsecancelexception_handlerstandardize_grants_dict
open(cls, connection)
open() is a classmethod that gets a connection object (which could be in any state, but will have a Credentials object with the attributes you defined above) and moves it to the 'open' state.
Generally this means doing the following:
- if the connection is open already, log and return it.
- If a database needed changes to the underlying connection before re-use, that would happen here
- create a connection handle using the underlying database library using the credentials
- on success:
- set connection.state to
'open' - set connection.handle to the handle object
- this is what must have a
cursor()method that returns a cursor!
- this is what must have a
- set connection.state to
- on error:
- set connection.state to
'fail' - set connection.handle to
None - raise a
dbt.exceptions.FailedToConnectExceptionwith the error and any other relevant information
- set connection.state to
- on success:
For example:
@classmethod
def open(cls, connection):
if connection.state == 'open':
logger.debug('Connection is already open, skipping open.')
return connection
credentials = connection.credentials
try:
handle = myadapter_library.connect(
host=credentials.host,
port=credentials.port,
username=credentials.username,
password=credentials.password,
catalog=credentials.database
)
connection.state = 'open'
connection.handle = handle
return connection
get_response(cls, cursor)
get_response is a classmethod that gets a cursor object and returns adapter-specific information about the last executed command. The return value should be an AdapterResponse object that includes items such as code, rows_affected, bytes_processed, and a summary _message for logging to stdout.
@classmethod
def get_response(cls, cursor) -> AdapterResponse:
code = cursor.sqlstate or "OK"
rows = cursor.rowcount
status_message = f"{code} {rows}"
return AdapterResponse(
_message=status_message,
code=code,
rows_affected=rows
)
cancel(self, connection)
cancel is an instance method that gets a connection object and attempts to cancel any ongoing queries, which is database dependent. Some databases don't support the concept of cancellation, they can simply implement it via 'pass' and their adapter classes should implement an is_cancelable that returns False - On ctrl+c connections may remain running. This method must be implemented carefully, as the affected connection will likely be in use in a different thread.
def cancel(self, connection):
tid = connection.handle.transaction_id()
sql = 'select cancel_transaction({})'.format(tid)
logger.debug("Cancelling query '{}' ({})".format(connection_name, pid))
_, cursor = self.add_query(sql, 'master')
res = cursor.fetchone()
logger.debug("Canceled query '{}': {}".format(connection_name, res))
exception_handler(self, sql, connection_name='master')
exception_handler is an instance method that returns a context manager that will handle exceptions raised by running queries, catch them, log appropriately, and then raise exceptions dbt knows how to handle.
If you use the (highly recommended) @contextmanager decorator, you only have to wrap a yield inside a try block, like so:
@contextmanager
def exception_handler(self, sql: str):
try:
yield
except myadapter_library.DatabaseError as exc:
self.release(connection_name)
logger.debug('myadapter error: {}'.format(str(e)))
raise dbt.exceptions.DatabaseException(str(exc))
except Exception as exc:
logger.debug("Error running SQL: {}".format(sql))
logger.debug("Rolling back transaction.")
self.release(connection_name)
raise dbt.exceptions.RuntimeException(str(exc))
standardize_grants_dict(self, grants_table: agate.Table) -> dict
standardize_grants_dict is an method that returns the dbt-standardized grants dictionary that matches how users configure grants now in dbt. The input is the result of SHOW GRANTS ON {{model}} call loaded into an agate table.
If there's any massaging of agate table containing the results, of SHOW GRANTS ON {{model}}, that can't easily be accomplished in SQL, it can be done here. For example, the SQL to show grants should filter OUT any grants TO the current user/role (e.g. OWNERSHIP). If that's not possible in SQL, it can be done in this method instead.
@available
def standardize_grants_dict(self, grants_table: agate.Table) -> dict:
"""
:param grants_table: An agate table containing the query result of
the SQL returned by get_show_grant_sql
:return: A standardized dictionary matching the `grants` config
:rtype: dict
"""
grants_dict: Dict[str, List[str]] = {}
for row in grants_table:
grantee = row["grantee"]
privilege = row["privilege_type"]
if privilege in grants_dict.keys():
grants_dict[privilege].append(grantee)
else:
grants_dict.update({privilege: [grantee]})
return grants_dict
Editing the adapter implementation
Edit the connection manager at myadapter/dbt/adapters/myadapter/impl.py
Very little is required to implement the adapter itself. On some adapters, you will not need to override anything. On others, you'll likely need to override some of the convert_* classmethods, or override the is_cancelable classmethod on others to return False.
datenow()
This classmethod provides the adapter's canonical date function. This is not used but is required– anyway on all adapters.
@classmethod
def date_function(cls):
return 'datenow()'
Editing SQL logic
dbt implements specific SQL operations using Jinja macros. While reasonable defaults are provided for many such operations (like create_schema, drop_schema, create_table, etc), you may need to override one or more of macros when building a new adapter.
Required macros
The following macros must be implemented, but you can override their behavior for your adapter using the "dispatch" pattern described below. Macros marked (required) do not have a valid default implementation, and are required for dbt to operate.
alter_column_type(source)check_schema_exists(source)create_schema(source)drop_relation(source)drop_schema(source)get_columns_in_relation(source) (required)list_relations_without_caching(source) (required)list_schemas(source)rename_relation(source)truncate_relation(source)current_timestamp(source) (required)copy_grants
Adapter dispatch
Most modern databases support a majority of the standard SQL spec. There are some databases that do not support critical aspects of the SQL spec however, or they provide their own nonstandard mechanisms for implementing the same functionality. To account for these variations in SQL support, dbt provides a mechanism called multiple dispatch for macros. With this feature, macros can be overridden for specific adapters. This makes it possible to implement high-level methods (like "create table") in a database-specific way.
{# dbt will call this macro by name, providing any arguments #}
{% macro create_table_as(temporary, relation, sql) -%}
{# dbt will dispatch the macro call to the relevant macro #}
{{ return(
adapter.dispatch('create_table_as')(temporary, relation, sql)
) }}
{%- endmacro %}
{# If no macro matches the specified adapter, "default" will be used #}
{% macro default__create_table_as(temporary, relation, sql) -%}
...
{%- endmacro %}
{# Example which defines special logic for Redshift #}
{% macro redshift__create_table_as(temporary, relation, sql) -%}
...
{%- endmacro %}
{# Example which defines special logic for BigQuery #}
{% macro bigquery__create_table_as(temporary, relation, sql) -%}
...
{%- endmacro %}
The adapter.dispatch() macro takes a second argument, packages, which represents a set of "search namespaces" in which to find potential implementations of a dispatched macro. This allows users of community-supported adapters to extend or "shim" dispatched macros from common packages, such as dbt-utils, with adapter-specific versions in their own project or other installed packages. See:
- "Shim" package examples:
spark-utils,tsql-utils adapter.dispatchdocs
Overriding adapter methods
While much of dbt's adapter-specific functionality can be modified in adapter macros, it can also make sense to override adapter methods directly. In this example, assume that a database does not support a cascade parameter to drop schema. Instead, we can implement an approximation where we drop each relation and then drop the schema.
def drop_schema(self, relation: BaseRelation):
relations = self.list_relations(
database=relation.database,
schema=relation.schema
)
for relation in relations:
self.drop_relation(relation)
super().drop_schema(relation)
Grants Macros
See this GitHub discussion for information on the macros required for GRANT statements:
Behavior change flags
Starting in dbt-adapters==1.5.0 and dbt-core==1.8.7, adapter maintainers can implement their own behavior change flags. Refer to Behavior changes for more information.
Behavior Flags are not intended to be long-living feature flags. They should be implemented with the expectation that the behavior will be the default within an expected period of time. To implement a behavior change flag, you must provide a name for the flag, a default setting (True / False), an optional source, and a description and/or a link to the flag's documentation on docs.getdbt.com.
We recommend having a description and documentation link whenever possible. The description and/or docs should provide end users context for why the flag exists, why they may see a warning, and why they may want to utilize the behavior flag. Behavior change flags can be implemented by overwriting _behavior_flags() on the adapter in impl.py:
class ABCAdapter(BaseAdapter):
...
@property
def _behavior_flags(self) -> List[BehaviorFlag]:
return [
{
"name": "enable_new_functionality_requiring_higher_permissions",
"default": False,
"source": "dbt-abc",
"description": (
"The dbt-abc adapter is implementing a new method for sourcing metadata. "
"This is a more performant way for dbt to source metadata but requires higher permissions on the platform. "
"Enabling this without granting the requisite permissions will result in an error. "
"This feature is expected to be required by Spring 2025."
),
"docs_url": "https://docs.getdbt.com/reference/global-configs/behavior-changes#abc-enable_new_functionality_requiring_higher_permissions",
}
]
Once a behavior change flag has been implemented, it can be referenced on the adapter both in impl.py and in Jinja macros:
class ABCAdapter(BaseAdapter):
...
def some_method(self, *args, **kwargs):
if self.behavior.enable_new_functionality_requiring_higher_permissions:
# do the new thing
else:
# do the old thing
{% macro some_macro(**kwargs) %}
{% if adapter.behavior.enable_new_functionality_requiring_higher_permissions %}
{# do the new thing #}
{% else %}
{# do the old thing #}
{% endif %}
{% endmacro %}
Every time the behavior flag evaluates to False, it warns the user, informing them that a change will occur in the future.
This warning doesn't display when the flag evaluates to True as the user is already in the new experience.
Recognizing that the warnings can be disruptive and are not always necessary, you can evaluate the flag without triggering the warning. Simply append .no_warn to the end of the flag.
class ABCAdapter(BaseAdapter):
...
def some_method(self, *args, **kwargs):
if self.behavior.enable_new_functionality_requiring_higher_permissions.no_warn:
# do the new thing
else:
# do the old thing
{% macro some_macro(**kwargs) %}
{% if adapter.behavior.enable_new_functionality_requiring_higher_permissions.no_warn %}
{# do the new thing #}
{% else %}
{# do the old thing #}
{% endif %}
{% endmacro %}
It's best practice to evaluate a behavior flag as few times as possible. This will make it easier to remove once the behavior change has matured.
As a result, evaluating the flag earlier in the logic flow is easier. Then, take either the old or the new path. While this may create some duplication in code, using behavior flags in this way provides a safer way to implement a change, which we are already admitting is risky or even breaking in nature.
Other files
profile_template.yml
In order to enable the dbt init command to prompt users when setting up a new project and connection profile, you should include a profile template. The filepath needs to be dbt/include/<adapter_name>/profile_template.yml. It's possible to provide hints, default values, and conditional prompts based on connection methods that require different supporting attributes. Users will also be able to include custom versions of this file in their own projects, with fixed values specific to their organization, to support their colleagues when using your dbt adapter for the first time.
See examples:
__version__.py
To assure that dbt --version provides the latest dbt core version the adapter supports, be sure include a __version__.py file. The filepath will be dbt/adapters/<adapter_name>/__version__.py. We recommend using the latest dbt core version and as the adapter is made compatible with later versions, this file will need to be updated. For a sample file, check out this example.
It should be noted that both of these files are included in the bootstrapped output of the dbt-database-adapter-scaffold so when using the scaffolding, these files will be included.
Test your adapter
This document has two sections:
- Refer to "About the testing framework" for a description of the standard framework that we maintain for using pytest together with dbt. It includes an example that shows the anatomy of a simple test case.
- Refer to "Testing your adapter" for a step-by-step guide for using our out-of-the-box suite of "basic" tests, which will validate that your adapter meets a baseline of dbt functionality.
Testing prerequisites
- Your adapter must be compatible with dbt Core v1.x v1.1 or newer
- You should be familiar with pytest: https://docs.pytest.org
About the testing framework
dbt-adapters-tests offers a standard framework for running prebuilt functional tests, and for defining your own tests. The core testing framework is built using pytest, a mature and standard library for testing Python projects.
It includes basic utilities for setting up pytest + dbt. These are used by all "prebuilt" functional tests, and make it possible to quickly write your own tests.
Those utilities allow you to do three basic things:
- Quickly set up a dbt "project." Define project resources via methods such as
models()andseeds(). Useproject_config_update()to pass configurations intodbt_project.yml. - Define a sequence of dbt commands. The most important utility is
run_dbt(), which returns the results of each dbt command. It takes a list of CLI specifiers (subcommand + flags), as well as an optional second argument,expect_pass=False, for cases where you expect the command to fail. - Validate the results of those dbt commands. For example,
check_relations_equal()asserts that two database objects have the same structure and content. You can also write your ownassertstatements, by inspecting the results of a dbt command, or querying arbitrary database objects withproject.run_sql().
You can see the full suite of utilities, with arguments and annotations, in util.py. You'll also see them crop up across a number of test cases. While all utilities are intended to be reusable, you won't need all of them for every test. In the example below, we'll show a simple test case that uses only a few utilities.
Example: a simple test case
This example will show you the anatomy of a test case using dbt + pytest. We will create reusable components, combine them to form a dbt "project", and define a sequence of dbt commands. Then, we'll use Python assert statements to ensure those commands succeed (or fail) as we expect.
In "Getting started running basic tests," we'll offer step-by-step instructions for installing and configuring pytest, so that you can run it on your own machine. For now, it's more important to see how the pieces of a test case fit together.
This example includes a seed, a model, and two tests—one of which will fail.
- Define Python strings that will represent the file contents in your dbt project. Defining these in a separate file enables you to reuse the same components across different test cases. The pytest name for this type of reusable component is "fixture."
# seeds/my_seed.csv
my_seed_csv = """
id,name,some_date
1,Easton,1981-05-20T06:46:51
2,Lillian,1978-09-03T18:10:33
3,Jeremiah,1982-03-11T03:59:51
4,Nolan,1976-05-06T20:21:35
""".lstrip()
# models/my_model.sql
my_model_sql = """
select * from {{ ref('my_seed') }}
union all
select null as id, null as name, null as some_date
"""
# models/my_model.yml
my_model_yml = """
version: 2
models:
- name: my_model
columns:
- name: id
data_tests:
- unique
- not_null # this test will fail
"""
- Use the "fixtures" to define the project for your test case. These fixtures are always scoped to the class, where the class represents one test case—that is, one dbt project or scenario. (The same test case can be used for one or more actual tests, which we'll see in step 3.) Following the default pytest configurations, the file name must begin with
test_, and the class name must begin withTest.
import pytest
from dbt.tests.util import run_dbt
# our file contents
from tests.functional.example.fixtures import (
my_seed_csv,
my_model_sql,
my_model_yml,
)
# class must begin with 'Test'
class TestExample:
"""
Methods in this class will be of two types:
1. Fixtures defining the dbt "project" for this test case.
These are scoped to the class, and reused for all tests in the class.
2. Actual tests, whose names begin with 'test_'.
These define sequences of dbt commands and 'assert' statements.
"""
# configuration in dbt_project.yml
@pytest.fixture(scope="class")
def project_config_update(self):
return {
"name": "example",
"models": {"+materialized": "view"}
}
# everything that goes in the "seeds" directory
@pytest.fixture(scope="class")
def seeds(self):
return {
"my_seed.csv": my_seed_csv,
}
# everything that goes in the "models" directory
@pytest.fixture(scope="class")
def models(self):
return {
"my_model.sql": my_model_sql,
"my_model.yml": my_model_yml,
}
# continues below
- Now that we've set up our project, it's time to define a sequence of dbt commands and assertions. We define one or more methods in the same file, on the same class (
TestExampleFailingTest), whose names begin withtest_. These methods share the same setup (project scenario) from above, but they can be run independently by pytest—so they shouldn't depend on each other in any way.
# continued from above
# The actual sequence of dbt commands and assertions
# pytest will take care of all "setup" + "teardown"
def test_run_seed_test(self, project):
"""
Seed, then run, then test. We expect one of the tests to fail
An alternative pattern is to use pytest "xfail" (see below)
"""
# seed seeds
results = run_dbt(["seed"])
assert len(results) == 1
# run models
results = run_dbt(["run"])
assert len(results) == 1
# test tests
results = run_dbt(["test"], expect_pass = False) # expect failing test
assert len(results) == 2
# validate that the results include one pass and one failure
result_statuses = sorted(r.status for r in results)
assert result_statuses == ["fail", "pass"]
@pytest.mark.xfail
def test_build(self, project):
"""Expect a failing test"""
# do it all
results = run_dbt(["build"])
- Our test is ready to run! The last step is to invoke
pytestfrom your command line. We'll walk through the actual setup and configuration ofpytestin the next section.
$ python3 -m pytest tests/functional/test_example.py
=========================== test session starts ============================
platform ... -- Python ..., pytest-..., pluggy-...
rootdir: ...
plugins: ...
tests/functional/test_example.py .X [100%]
======================= 1 passed, 1 xpassed in 1.38s =======================
You can find more ways to run tests, along with a full command reference, in the pytest usage docs.
We've found the -s flag (or --capture=no) helpful to print logs from the underlying dbt invocations, and to step into an interactive debugger if you've added one. You can also use environment variables to set global dbt configs, such as (to show debug-level logs).
Testing this adapter
Anyone who installs dbt-core, and wishes to define their own test cases, can use the framework presented in the first section. The framework is especially useful for testing standard dbt behavior across different databases.
To that end, we have built and made available a package of reusable adapter test cases, for creators and maintainers of adapter plugins. These test cases cover basic expected functionality, as well as functionality that frequently requires different implementations across databases.
For the time being, this package is also located within the dbt-core repository, but separate from the dbt-core Python package.
Categories of tests
In the course of creating and maintaining your adapter, it's likely that you will end up implementing tests that fall into three broad categories:
-
Basic tests that every adapter plugin is expected to pass. These are defined in
tests.adapter.basic. Given differences across data platforms, these may require slight modification or reimplementation. Significantly overriding or disabling these tests should be with good reason, since each represents basic functionality expected by dbt users. For example, if your adapter does not support incremental models, you should disable the test, by marking it withskiporxfail, as well as noting that limitation in any documentation, READMEs, and usage guides that accompany your adapter. -
Optional tests, for second-order functionality that is common across plugins, but not required for basic use. Your plugin can opt into these test cases by inheriting existing ones, or reimplementing them with adjustments. For now, this category includes all tests located outside the
basicsubdirectory. More tests will be added as we convert older tests defined on dbt-core and mature plugins to use the standard framework. -
Custom tests, for behavior that is specific to your adapter / data platform. Each data warehouse has its own specialties and idiosyncracies. We encourage you to use the same
pytest-based framework, utilities, and fixtures to write your own custom tests for functionality that is unique to your adapter.
If you run into an issue with the core framework, or the basic/optional test cases—or if you've written a custom test that you believe would be relevant and useful for other adapter plugin developers—please open an issue or PR in the dbt-core repository on GitHub.
Getting started running basic tests
In this section, we'll walk through the three steps to start running our basic test cases on your adapter plugin:
- Install dependencies
- Set up and configure pytest
- Define test cases
Install dependencies
You should already have a virtual environment with dbt-core and your adapter plugin installed. You'll also need to install:
pytestdbt-tests-adapter, the set of common test cases- (optional)
pytestplugins--we'll usepytest-dotenvbelow
Or specify all dependencies in a requirements file like:
pytest
pytest-dotenv
dbt-tests-adapter
python -m pip install -r dev_requirements.txt
Set up and configure pytest
First, set yourself up to run pytest by creating a file named pytest.ini at the root of your repository:
[pytest]
filterwarnings =
ignore:.*'soft_unicode' has been renamed to 'soft_str'*:DeprecationWarning
ignore:unclosed file .*:ResourceWarning
env_files =
test.env # uses pytest-dotenv plugin
# this allows you to store env vars for database connection in a file named test.env
# rather than passing them in every CLI command, or setting in `PYTEST_ADDOPTS`
# be sure to add "test.env" to .gitignore as well!
testpaths =
tests/functional # name per convention
Then, create a configuration file within your tests directory. In it, you'll want to define all necessary profile configuration for connecting to your data platform in local development and continuous integration. We recommend setting these values with environment variables, since this file will be checked into version control.
import pytest
import os
# Import the standard functional fixtures as a plugin
# Note: fixtures with session scope need to be local
pytest_plugins = ["dbt.tests.fixtures.project"]
# The profile dictionary, used to write out profiles.yml
# dbt will supply a unique schema per test, so we do not specify 'schema' here
@pytest.fixture(scope="class")
def dbt_profile_target():
return {
'type': '<myadapter>',
'threads': 1,
'host': os.getenv('HOST_ENV_VAR_NAME'),
'user': os.getenv('USER_ENV_VAR_NAME'),
...
}
Define test cases
As in the example above, each test case is defined as a class, and has its own "project" setup. To get started, you can import all basic test cases and try running them without changes.
import pytest
from dbt.tests.adapter.basic.test_base import BaseSimpleMaterializations
from dbt.tests.adapter.basic.test_singular_tests import BaseSingularTests
from dbt.tests.adapter.basic.test_singular_tests_ephemeral import BaseSingularTestsEphemeral
from dbt.tests.adapter.basic.test_empty import BaseEmpty
from dbt.tests.adapter.basic.test_ephemeral import BaseEphemeral
from dbt.tests.adapter.basic.test_incremental import BaseIncremental
from dbt.tests.adapter.basic.test_generic_tests import BaseGenericTests
from dbt.tests.adapter.basic.test_snapshot_check_cols import BaseSnapshotCheckCols
from dbt.tests.adapter.basic.test_snapshot_timestamp import BaseSnapshotTimestamp
from dbt.tests.adapter.basic.test_adapter_methods import BaseAdapterMethod
class TestSimpleMaterializationsMyAdapter(BaseSimpleMaterializations):
pass
class TestSingularTestsMyAdapter(BaseSingularTests):
pass
class TestSingularTestsEphemeralMyAdapter(BaseSingularTestsEphemeral):
pass
class TestEmptyMyAdapter(BaseEmpty):
pass
class TestEphemeralMyAdapter(BaseEphemeral):
pass
class TestIncrementalMyAdapter(BaseIncremental):
pass
class TestGenericTestsMyAdapter(BaseGenericTests):
pass
class TestSnapshotCheckColsMyAdapter(BaseSnapshotCheckCols):
pass
class TestSnapshotTimestampMyAdapter(BaseSnapshotTimestamp):
pass
class TestBaseAdapterMethod(BaseAdapterMethod):
pass
Finally, run pytest:
python3 -m pytest tests/functional
Modifying test cases
You may need to make slight modifications in a specific test case to get it passing on your adapter. The mechanism to do this is simple: rather than simply inheriting the "base" test with pass, you can redefine any of its fixtures or test methods.
For instance, on Redshift, we need to explicitly cast a column in the fixture input seed to use data type varchar(64):
import pytest
from dbt.tests.adapter.basic.files import seeds_base_csv, seeds_added_csv, seeds_newcolumns_csv
from dbt.tests.adapter.basic.test_snapshot_check_cols import BaseSnapshotCheckCols
# set the datatype of the name column in the 'added' seed so it
# can hold the '_update' that's added
schema_seed_added_yml = """
version: 2
seeds:
- name: added
config:
column_types:
name: varchar(64)
"""
class TestSnapshotCheckColsRedshift(BaseSnapshotCheckCols):
# Redshift defines the 'name' column such that it's not big enough
# to hold the '_update' added in the test.
@pytest.fixture(scope="class")
def models(self):
return {
"base.csv": seeds_base_csv,
"added.csv": seeds_added_csv,
"seeds.yml": schema_seed_added_yml,
}
As another example, the dbt-bigquery adapter asks users to "authorize" replacing a table with a view by supplying the --full-refresh flag. The reason: In the table materialization logic, a view by the same name must first be dropped; if the table query fails, the model will be missing.
Knowing this possibility, the "base" test case offers a require_full_refresh switch on the test_config fixture class. For BigQuery, we'll switch it on:
import pytest
from dbt.tests.adapter.basic.test_base import BaseSimpleMaterializations
class TestSimpleMaterializationsBigQuery(BaseSimpleMaterializations):
@pytest.fixture(scope="class")
def test_config(self):
# effect: add '--full-refresh' flag in requisite 'dbt run' step
return {"require_full_refresh": True}
It's always worth asking whether the required modifications represent gaps in perceived or expected dbt functionality. Are these simple implementation details, which any user of this database would understand? Are they limitations worth documenting?
If, on the other hand, they represent poor assumptions in the "basic" test cases, which fail to account for a common pattern in other types of databases-—please open an issue or PR in the dbt-core repository on GitHub.
Running with multiple profiles
Some databases support multiple connection methods, which map to actually different functionality behind the scenes. For instance, the dbt-spark adapter supports connections to Apache Spark clusters and Databricks runtimes, which supports additional functionality out of the box, enabled by the Delta file format.
def pytest_addoption(parser):
parser.addoption("--profile", action="store", default="apache_spark", type=str)
# Using @pytest.mark.skip_profile('apache_spark') uses the 'skip_by_profile_type'
# autouse fixture below
def pytest_configure(config):
config.addinivalue_line(
"markers",
"skip_profile(profile): skip test for the given profile",
)
@pytest.fixture(scope="session")
def dbt_profile_target(request):
profile_type = request.config.getoption("--profile")
elif profile_type == "databricks_sql_endpoint":
target = databricks_sql_endpoint_target()
elif profile_type == "apache_spark":
target = apache_spark_target()
else:
raise ValueError(f"Invalid profile type '{profile_type}'")
return target
def apache_spark_target():
return {
"type": "spark",
"host": "localhost",
...
}
def databricks_sql_endpoint_target():
return {
"type": "spark",
"host": os.getenv("DBT_DATABRICKS_HOST_NAME"),
...
}
@pytest.fixture(autouse=True)
def skip_by_profile_type(request):
profile_type = request.config.getoption("--profile")
if request.node.get_closest_marker("skip_profile"):
for skip_profile_type in request.node.get_closest_marker("skip_profile").args:
if skip_profile_type == profile_type:
pytest.skip("skipped on '{profile_type}' profile")
If there are tests that shouldn't run for a given profile:
# Snapshots require access to the Delta file format, available on our Databricks connection,
# so let's skip on Apache Spark
@pytest.mark.skip_profile('apache_spark')
class TestSnapshotCheckColsSpark(BaseSnapshotCheckCols):
@pytest.fixture(scope="class")
def project_config_update(self):
return {
"seeds": {
"+file_format": "delta",
},
"snapshots": {
"+file_format": "delta",
}
}
Finally:
python3 -m pytest tests/functional --profile apache_spark
python3 -m pytest tests/functional --profile databricks_sql_endpoint
Document a new adapter
If you've already built, and tested your adapter, it's time to document it so the dbt community will know that it exists and how to use it.
Making your adapter available
Many community members maintain their adapter plugins under open source licenses. If you're interested in doing this, we recommend:
- Hosting on a public git provider (for example, GitHub or Gitlab)
- Publishing to PyPI
- Adding to the list of "Supported Data Platforms" (more info below)
General Guidelines
To best inform the dbt community of the new adapter, you should contribute to the dbt's open-source documentation site, which uses the Docusaurus project. This is the site you're currently on!
Conventions
Each .md file you create needs a header as shown below. The document id will also need to be added to the config file: website/sidebars.js.
---
title: "Documenting a new adapter"
id: "documenting-a-new-adapter"
---
Single Source of Truth
We ask our adapter maintainers to use the docs.getdbt.com repo (i.e. this site) as the single-source-of-truth for documentation rather than having to maintain the same set of information in three different places. The adapter repo's README.md and the data platform's documentation pages should simply link to the corresponding page on this docs site. Keep reading for more information on what should and shouldn't be included on the dbt docs site.
Assumed Knowledge
To simplify things, assume the reader of this documentation already knows how both dbt and your data platform works. There's already great material for how to learn dbt and the data platform out there. The documentation we're asking you to add should be what a user who is already profiecient in both dbt and your data platform would need to know in order to use both. Effectively that boils down to two things: how to connect, and how to configure.
Topics and Pages to Cover
The following subjects need to be addressed across three pages of this docs site to have your data platform be listed on our documentation. After the corresponding pull request is merged, we ask that you link to these pages from your adapter repo's README as well as from your product documentation.
To contribute, all you will have to do make the changes listed in the table below.
| Loading table... |
For example say I want to document my new adapter: dbt-ders. For the "Connect" page, I will make a new Markdown file, ders-setup.md and add it to the /website/docs/local/connect-data-platform/ directory.
Example PRs to add new adapter documentation
Below are some recent pull requests made by partners to document their data platform's adapter:
Note — Use the following re-usable component to auto-fill the frontmatter content on your new page:
import SetUpPages from '/snippets/_setup-pages-intro.md';
<SetUpPages meta={frontMatter.meta} />
Promote a new adapter
The most important thing here is recognizing that people are successful in the community when they join, first and foremost, to engage authentically.
What does authentic engagement look like? It’s challenging to define explicit rules. One good rule of thumb is to treat people with dignity and respect.
Contributors to the community should think of contribution as the end itself, not a means toward other business KPIs (leads, community members, etc.). We are a mission-driven company. Some ways to know if you’re authentically engaging:
- Is an engagement’s primary purpose of sharing knowledge and resources or building brand engagement?
- Imagine you didn’t work at the org you do — can you imagine yourself still writing this?
- Is it written in formal / marketing language, or does it sound like you, the human?
Who should join the dbt community slack?
-
People who have insight into what it means to do hands-on analytics engineering work The dbt Community Slack workspace is fundamentally a place for analytics practitioners to interact with each other — the closer the users are in the community to actual data/analytics engineering work, the more natural their engagement will be (leading to better outcomes for partners and the community).
-
DevRel practitioners with strong focus DevRel practitioners often have a strong analytics background and a good understanding of the community. It’s essential to be sure they are focused on contributing, not on driving community metrics for partner org (such as signing people up for their slack or events). The metrics will rise naturally through authentic engagement.
-
Founder and executives who are interested in directly engaging with the community This is either incredibly successful or not at all depending on the profile of the founder. Typically, this works best when the founder has a practitioner-level of technical understanding and is interested in joining not to promote, but to learn and hear from users.
-
Software Engineers at partner products that are building and supporting integrations with either dbt Core v1.x or the dbt platform This is successful when the engineers are familiar with dbt as a product or at least have taken our training course. The Slack is often a place where end-user questions and feedback is initially shared, so it is recommended that someone technical from the team be present. There are also a handful of channels aimed at those building integrations, which tend to be a font of knowledge.
Who might struggle in the dbt community
-
People in marketing roles dbt Slack is not a marketing channel. Attempts to use it as such invariably fall flat and can even lead to people having a negative view of a product. This doesn’t mean that dbt can’t serve marketing objectives, but a long-term commitment to engagement is the only proven method to do this sustainably.
-
People in product roles The dbt Community can be an invaluable source of feedback on a product. There are two primary ways this can happen — organically (community members proactively suggesting a new feature) and via direct calls for feedback and user research. Immediate calls for engagement must be done in your dedicated #tools channel. Direct calls should be used sparingly, as they can overwhelm more organic discussions and feedback.
Who is the audience for an adapter release?
A new adapter is likely to drive huge community interest from several groups of people:
- People who are currently using the database that the adapter is supporting
- People who may be adopting the database in the near future.
- People who are interested in dbt development in general.
The database users will be your primary audience and the most helpful in achieving success. Engage them directly in the adapter’s dedicated Slack channel. If one does not exist already, reach out in #channel-requests, and we will get one made for you and include it in an announcement about new channels.
The final group is where non-slack community engagement becomes important. Twitter and LinkedIn are both great places to interact with a broad audience. A well-orchestrated adapter release can generate impactful and authentic engagement.
How to message the initial rollout and follow-up content
Tell a story that engages dbt users and the community. Highlight new use cases and functionality unlocked by the adapter in a way that will resonate with each segment.
-
Existing users of your technology who are new to dbt
- Provide a general overview of the value dbt will deliver to your users. This can lean on dbt's messaging and talking points which are laid out in the dbt viewpoint.
- Give examples of a rollout that speaks to the overall value of dbt and your product.
-
Users who are already familiar with dbt and the community
- Consider unique use cases or advantages your adapter provide over existing adapters. Who will be excited for this?
- Contribute to the dbt Community and ensure that dbt users on your adapter are well supported (tutorial content, packages, documentation, etc).
- Example of a rollout that is compelling for those familiar with dbt: Firebolt
Tactically manage distribution of content about new or existing adapters
There are tactical pieces on how and where to share that help ensure success.
-
On slack:
- #i-made-this channel — this channel has a policy against “marketing” and “content marketing” posts, but it should be successful if you write your content with the above guidelines in mind. Even with that, it’s important to post here sparingly.
- Your own database / tool channel — this is where the people who have opted in to receive communications from you and always a great place to share things that are relevant to them.
-
On social media:
- Social media posts from the author or an individual connected to the project tend to have better engagement than posts from a company or organization account.
- Ask your partner representative about:
- Retweets and shares from the official dbt Labs accounts.
- Flagging posts internally at dbt Labs to get individual employees to share.
Measuring engagement
You don’t need 1000 people in a channel to succeed, but you need at least a few active participants who can make it feel lived in. If you’re comfortable working in public, this could be members of your team, or it can be a few people who you know that are highly engaged and would be interested in participating. Having even 2 or 3 regulars hanging out in a channel is all that’s needed for a successful start and is, in fact, much more impactful than 250 people that never post.
How to announce a new adapter
We’d recommend against boilerplate announcements and encourage finding a unique voice. That being said, there are a couple of things that we’d want to include:
- A summary of the value prop of your database / technology for users who aren’t familiar.
- The personas that might be interested in this news.
- A description of what the adapter is. For example:
With the release of our new dbt adapter, you’ll be able to to use dbt to model and transform your data in [name-of-your-org]
- Particular or unique use cases or functionality unlocked by the adapter.
- Plans for future / ongoing support / development.
- The link to the documentation for using the adapter on the dbt Labs docs site.
- An announcement blog.
Announcing new release versions of existing adapters
This can vary substantially depending on the nature of the release but a good baseline is the types of release messages that we put out in the #dbt-releases channel.
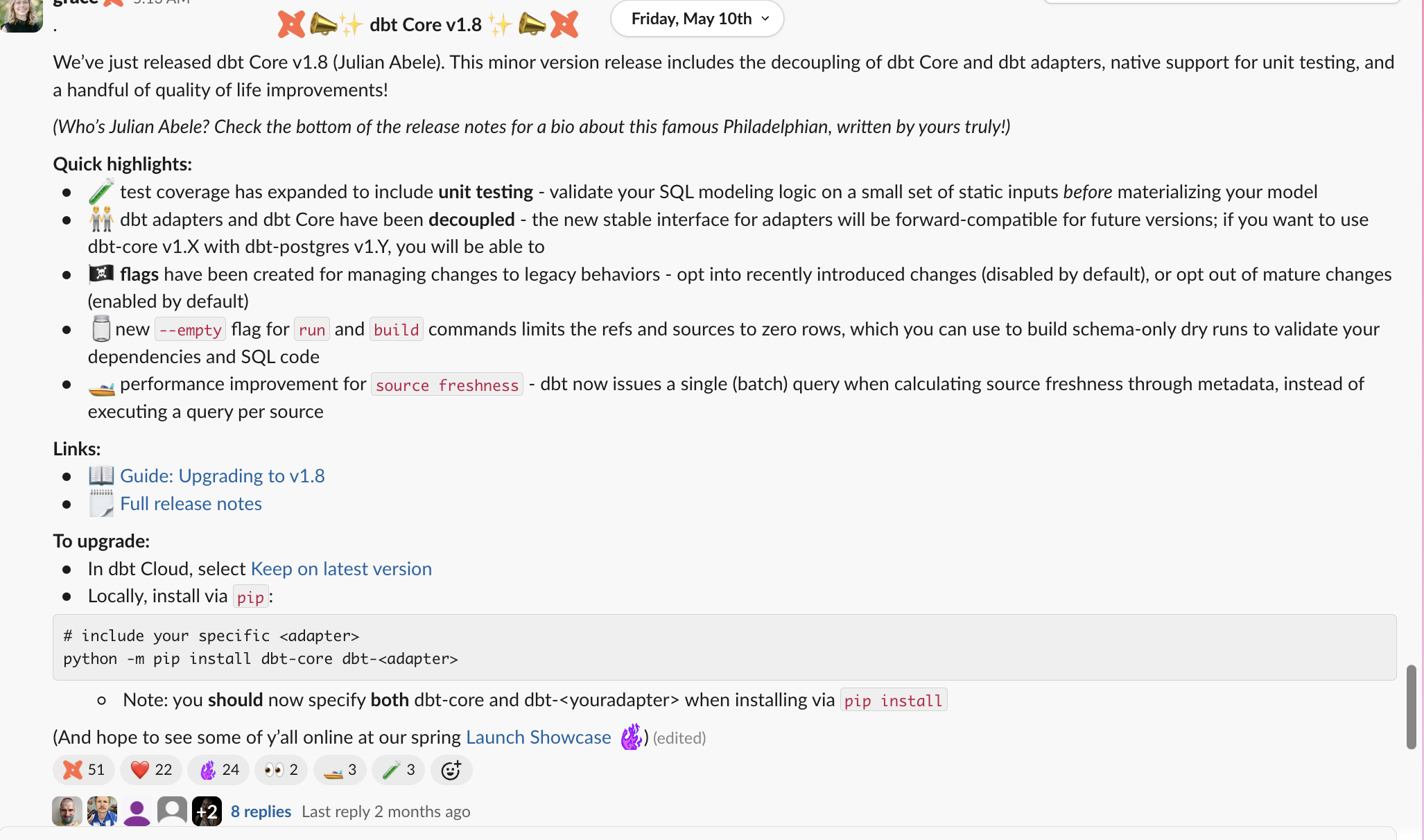
Breaking this down:
- Visually distinctive announcement - make it clear this is a release
 title
title - Short written description of what is in the release
 description
description - Links to additional resources
 more resources
more resources - Implementation instructions:
 more installation
more installation - Contributor recognition (if applicable)
 thank yous
thank yous
Build a trusted adapter
The Trusted Adapter Program exists to allow adapter maintainers to demonstrate to the dbt community that your adapter is trusted to be used in production.
The very first data platform dbt supported was Redshift followed quickly by Postgres (dbt-core#174). In 2017, back when dbt Labs (née Fishtown Analytics) was still a data consultancy, we added support for Snowflake and BigQuery. We also turned dbt's database support into an adapter framework (dbt-core#259), and a plugin system a few years later. For years, dbt Labs specialized in those four data platforms and became experts in them. However, the surface area of all possible databases, their respective nuances, and keeping them up-to-date and bug-free is a Herculean and/or Sisyphean task that couldn't be done by a single person or even a single team! Enter the dbt community which enables dbt Core v1.x to work on more than 30 different databases (32 as of Sep '22)!
Free and open-source tools for the data professional are increasingly abundant. This is by-and-large a good thing, however it requires due diligence that wasn't required in a paid-license, closed-source software world. Before taking a dependency on an open-source project is is important to determine the answer to the following questions:
- Does it work?
- Does it meet my team's specific use case?
- Does anyone "own" the code, or is anyone liable for ensuring it works?
- Do bugs get fixed quickly?
- Does it stay up-to-date with new Core features?
- Is the usage substantial enough to self-sustain?
- What risks do I take on by taking a dependency on this library?
These are valid, important questions to answer—especially given that dbt-core itself only put out its first stable release (major version v1.0) in December 2021! Indeed, up until now, the majority of new user questions in database-specific channels are some form of:
- "How mature is
dbt-<ADAPTER>? Any gotchas I should be aware of before I start exploring?" - "has anyone here used
dbt-<ADAPTER>for production models?" - "I've been playing with
dbt-<ADAPTER>-- I was able to install and run my initial experiments. I noticed that there are certain features mentioned on the documentation that are marked as 'not ok' or 'not tested'. What are the risks? I'd love to make a statement on my team to adopt dbt, but I'm pretty sure questions will be asked around the possible limitations of the adapter or if there are other companies out there using dbt with Oracle DB in production, etc."
There has been a tendency to trust the dbt Labs-maintained adapters over community- and vendor-supported adapters, but repo ownership is only one among many indicators of software quality. We aim to help our users feel well-informed as to the caliber of an adapter with a new program.
What it means to be trusted
By opting into the below, you agree to this, and we take you at your word. dbt Labs reserves the right to remove an adapter from the trusted adapter list at any time, should any of the below guidelines not be met.
Feature Completeness
To be considered for the Trusted Adapter Program, the adapter must cover the essential functionality of dbt Core v1.x given below, with best effort given to support the entire feature set.
Essential functionality includes (but is not limited to the following features):
- table, view, and seed materializations
- dbt tests
The adapter should have the required documentation for connecting and configuring the adapter. The dbt docs site should be the single source of truth for this information. These docs should be kept up-to-date.
Proceed to the "Document a new adapter" step for more information.
Release cadence
Keeping an adapter up-to-date with the latest features of dbt, as defined in dbt-adapters, is an integral part of being a trusted adapter. We encourage adapter maintainers to keep track of new dbt-adapter releases and support new features relevant to their platform, ensuring users have the best version of dbt.
Before dbt Core v1.x version 1.8, adapter versions needed to match the semantic versioning of dbt Core v1.x. After v1.8, this is no longer required. This means users can use an adapter on v1.8+ with a different version of dbt Core v1.x v1.8+. For example, a user could use dbt-core v1.9 with dbt-postgres v1.8.
Community responsiveness
On a best effort basis, active participation and engagement with the dbt Community across the following forums:
- Being responsive to feedback and supporting user enablement in dbt Community’s Slack workspace
- Responding with comments to issues raised in public dbt adapter code repository
- Merging in code contributions from community members as deemed appropriate
Security Practices
Trusted adapters will not do any of the following:
- Output to logs or file either access credentials information to or data from the underlying data platform itself.
- Make API calls other than those expressly required for using dbt features (adapters may not add additional logging)
- Obfuscate code and/or functionality so as to avoid detection
Additionally, to avoid supply-chain attacks:
- Use an automated service to keep Python dependencies up-to-date (such as Dependabot or similar),
- Publish directly to PyPI from the dbt adapter code repository by using trusted CI/CD process (such as GitHub actions)
- Restrict admin access to both the respective code (GitHub) and package (PyPI) repositories
- Identify and mitigate security vulnerabilities by use of a static code analyzing tool (such as Snyk) as part of a CI/CD process
Other considerations
The adapter repository is:
- open-souce licensed,
- published to PyPI, and
- automatically tests the codebase against dbt Lab's provided adapter test suite
How to get an adapter on the trusted list
Open an issue on the docs.getdbt.com GitHub repository using the "Add adapter to Trusted list" template. In addition to contact information, it will ask confirm that you agree to the following.
- my adapter meet the guidelines given above
- I will make best reasonable effort that this continues to be so
- checkbox: I acknowledge that dbt Labs reserves the right to remove an adapter from the trusted adapter list at any time, should any of the above guidelines not be met.
The approval workflow is as follows:
- create and populate the template-created issue
- dbt Labs will respond as quickly as possible (maximally four weeks, though likely faster)
- If approved, dbt Labs will create and merge a Pull request to formally add the adapter to the list.
Getting help for my trusted adapter
Ask your question in #adapter-ecosystem channel of the dbt community Slack.
Was this page helpful?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.