From the Slack Archives: When Backend Devs Spark Joy for Data Folks

"I forgot to mention we dropped that column and created a new one for it!”
“Hmm, I’m actually not super sure why customer_id is passed as an int and not a string.”
“The primary key for that table is actually the order_id, not the id field.”
I think many analytics engineers, including myself, have been on the receiving end of some of these comments from their backend application developers.
Backend developers work incredibly hard. They create the database and tables that drive the heart of many businesses. In their efforts, they can sometimes overlook, forget, or not understand their impact on analytics work. However, when backend developers do understand and implement the technical and logistical requirements from data teams, they can spark joy.
So what makes strong collaboration possible between analytics engineers and backend application developers?
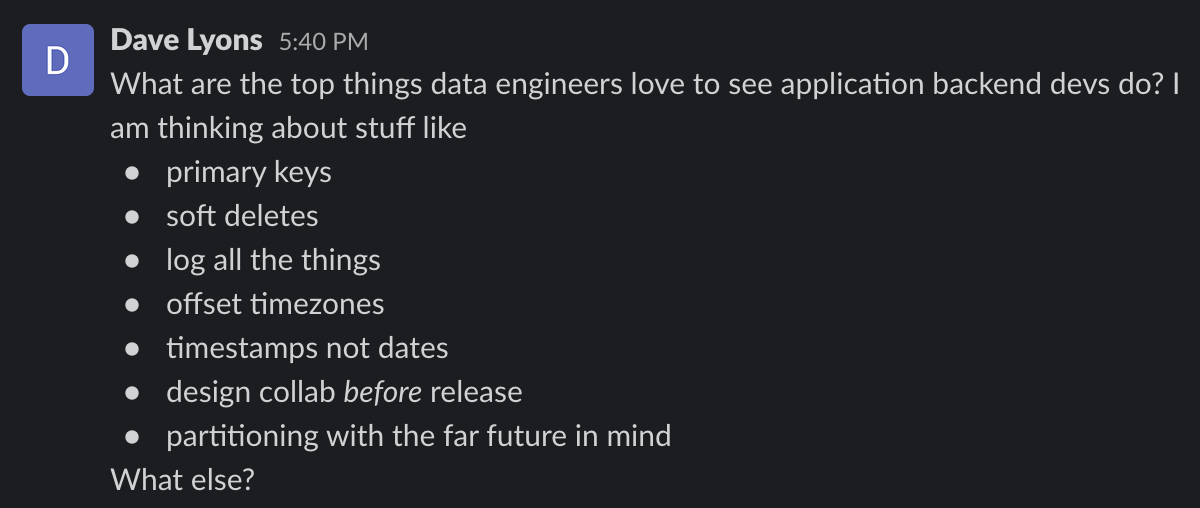 A screenshot of the conversation that started the thread
A screenshot of the conversation that started the thread
When the pieces fall into place
A recent slack thread in the dbt Community slack went over some of the technical and logistical aspects that can lead to happy data folks. Here were some of my favorite rules of the road that backend developers can follow to help them enjoy a quieter Slack.
Signs the data is sparking joy
All tables have a primary key.
Having columns in your tables that uniquely identify each row is fundamental to analytics work. Primary keys ensure there are no duplicates in the data, ultimately allowing for accurate counts. This is especially important for backend application database tables, since many organizations consider those tables to be their “source of truth” for backend application data. It’s even better when primary key fields are clearly identifiable in backend application tables!
Time-based fields are passed as timestamps, not dates.
Time-based fields, such as when an account is created or an order is placed, should be passed as timestamps. This format provides the most flexibility and granularity for analytics engineers and end business users. Timestamps can be made into accurate dates, date type fields cannot be made into accurate timestamps. Bonus points: When backend application tables have accurate created_at and updated_at fields, it’s a win for everyone.
There are consistent naming conventions for tables and fields.
Having a consistent method to name tables and fields for backend data is incredibly important for the readability and scalability of both backend application tables and data models.
Soft deletes FTW.
In a soft delete, data is noted as deleted in a type of deleted_at/is_deleted field. A hard delete performs a true deletion which ultimately removes the row from the table. Soft deletes and fields that specify whether rows were removed provide a true record of what is happening to the data. They establish greater context into backend application data and help analytics engineers ensure higher data quality.
Data is passed as the proper type.
Fields that are strings should be strings! And ints should be ints! Completing funky casts of fields in your data models is sometimes inevitable, but limiting where those complexities happen makes data modeling more intuitive.
“I looked back at the list above and I didn't see 'proper data typing' explicitly called out. I've seen so many cases of strings when it should be an int or a decimal or date or whatever else.” - a comment in the slack thread from Josh Andrews
Signs that operations are sparking joy
Communication and collaboration before releases is the norm.
Analytics engineers can catch release changes that may break their models prior to release by having routine communication with backend developers. Consider monitoring or reviewing PRs for backend work to understand the magic beneath the hood! In addition, collaboration between backend and analytics teams can encourage backend developers to establish a mindset where they frequently think about how their work will impact downstream analytics.
Don’t forget the documentation.
Regularly maintained and well-written documentation for backend application database tables helps analytics engineers and backend developers alike unpack complex data and data models. Documentation for backend application database tables might look like an entity relationship diagram (ERD) or an ERD supplemented with a living text-document providing greater detail into tables and fields. Furthermore, strong documentation helps analytics engineers write more descriptive documentation for source models in dbt.
A match made in heaven
Maintaining a strong and collaborative relationship with your backend application developers is hard. Forming the technical and logistical requirements that satisfy both parties is also challenging. However, taking the time to clearly define and understand why these requirements should exist is extremely rewarding and worth every difficult conversation. When done right, this kind of collaboration can lead to better partnership, more readable data models, higher quality data, and happier team members.
Want to read more about what makes data modeling a joy? Make sure to join the dbt Community slack!