Migrating from Stored Procedures to dbt

Stored procedures are widely used throughout the data warehousing world. They’re great for encapsulating complex transformations into units that can be scheduled and respond to conditional logic via parameters. However, as teams continue building their transformation logic using the stored procedure approach, we see more data downtime, increased data warehouse costs, and incorrect / unavailable data in production. All of this leads to more stressed and unhappy developers, and consumers who have a hard time trusting their data.
If your team works heavily with stored procedures, and you ever find yourself with the following or related issues:
- dashboards that aren’t refreshed on time
- It feels too slow and risky to modify pipeline code based on requests from your data consumers
- It’s hard to trace the origins of data in your production reporting
It’s worth considering if an alternative approach with dbt might help.
Why use modular dbt models instead of stored procedures?
We work with many analytics teams to refactor their stored procedure code into dbt. Many of them come in thinking that the upfront effort to modernize their approach to data transformation will be too much to justify. However, we see that in the long term this isn’t the case.
For example, a dbt Cloud user achieved the following results when moving away from the stored procedure approach:
Improved Uptime
Before migrating to dbt, the team was spending 6 - 8 hours per day on pipeline refreshes, making their investment in their data warehouse essentially worthless during that downtime. After migration, their uptime increased from 65% to 99.9%. This also has a drastic impact on data consumers’ confidence in the underlying pipelines.
Tackling New Use Cases
Further, the team was able to support new mission-critical use cases, which simply wouldn’t have been possible had the team continued using the same techniques they had historically.
Now that we’ve discussed why moving from stored procs to dbt can make sense for many analytics teams, let’s discuss how the process works in a bit more detail.
What are the problems with stored procedures?
Some of the drawbacks to using stored procedures may not have been apparent historically, but they come to light when we consider modern expectations of data pipelines such as transparent documentation, testability, and reusability of code. For one, stored procedures don’t lend themselves well to documenting data flow, as the intermediate steps are a black box. Secondly, this also means that your stored procedures aren’t very testable. Finally, we often see logic from intermediate steps in one stored procedure copied almost line-for-line to others! This creates extra bloat across a development team’s codebase, which drags down team efficiency.
We might visualize this situation as something like this:
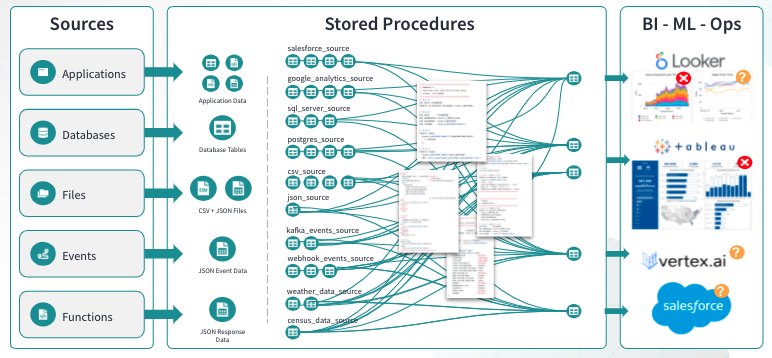
Why consider dbt as an alternative?
dbt offers an approach that is self-documenting, testable, and encourages code reuse during development. One of the most important elements of working in dbt is embracing modularity when approaching data pipelines. In dbt, each business object managed by a data pipeline is defined in a separate model (think: orders data). These models are flexibly grouped into layers to reflect the progression from raw to consumption ready data. Working in this way, we create reusable components which helps avoid duplicating data and confusion among development teams.
With dbt, we work towards creating simpler, more transparent data pipelines like this:
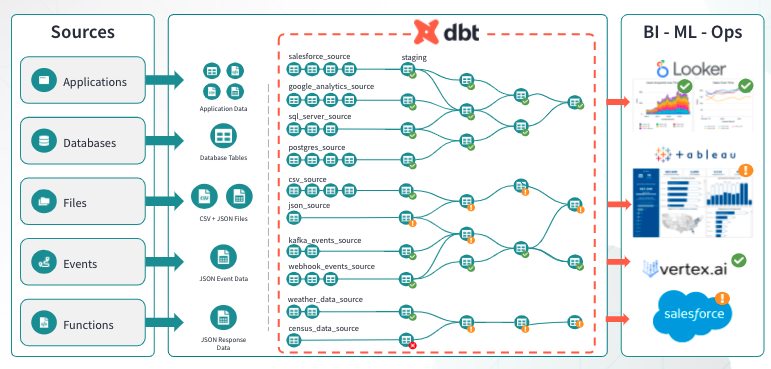
Tight version control integration is an added benefit of working with dbt. By leveraging the power of git-based tools, dbt enables you to integrate and test changes to transformation pipelines much faster than you can with other approaches. We often see teams who work in stored procedures making changes to their code without any notion of tracking those changes over time. While that’s more of an issue with the team’s chosen workflow than a problem with stored procedures per se, it does reflect how legacy tooling makes analytics work harder than necessary.
Methodologies for migrating from stored procedures to dbt
Whether you’re working with T-SQL, PL/SQL, BTEQ, or some other SQL dialect, the process of migrating from the stored procedure approach to the dbt approach can typically be broken down into similar steps. Over the years, we’ve worked with many customers to convert confusing and hard-to-manage stored procedure code into modular dbt pipelines. Through our work, we’ve arrived at a few key best practices in undertaking this process, which we present below.
If you’re interested in diving into further detail on this topic, please visit our companion guide to learn more in-depth information about the refactoring process.
Step 0: Understand a bit about how dbt works
If this is your first time running dbt, you may want to start with the Introduction to dbt and the Getting Started tutorial before diving into refactoring. If you’re already familiar with building dbt models and pipelines, feel free to dive in!
Step 1: Understand how dbt and stored procedures are different
Most folks who have written Stored Procedures in the past think about the world in terms of a stateful process that progresses line-by-line. You start out creating your tables, and then use DML to insert, update, and delete data, continually applying operations to the same base table throughout the course of a transformation.
On the other hand, dbt takes a declarative approach to managing datasets by using SELECT statements to describe the set of data that should make up the table. The tables (or views) defined in this way represent each stage or unit of transformation work, and are assembled into a Directed Acyclic Graph (DAG) to determine the order in which each statement runs. As we’ll see, this achieves the same ends as procedural transformations, but instead of applying many operations to one dataset, we take a more modular approach. This makes it MUCH easier to reason about, document, and test transformation pipelines.
Step 2: Plan how to convert your stored procedure to dbt code
In general, we've found that the recipe presented below is an effective conversion process.
- Map data flows in the stored procedure
- Identify raw source data
- Create a staging layer on top of raw sources for initial data transformations such as data type casting, renaming, etc.
- Replace hard-coded table references with dbt source() and ref() statements. This enables 1) ensuring things are run in the right order and 2) automatic documentation!
- Map INSERTS and UPDATES in the stored procedure to SELECT in dbt models
- Map DELETES in the stored procedure to WHERE filters in dbt models
- If necessary, use variables in dbt to dynamically assign values at runtime, similar to arguments passed to a stored procedure.
- Iterate on your process to refine the dbt DAG further. You could continue optimizing forever, but typically we find a good stopping point when the outputs from the stored procedure and final dbt models are at parity.
Sometimes, we find ourselves confronted with code that’s so complex, the end user isn’t able to understand exactly what it’s doing. In these cases, it may not be possible to perform an apples-to-apples mapping of the process embedded in the original stored procedure, and it’s actually more efficient to scrap the whole thing and focus on working backwards to reproduce the desired output in dbt. Note the section on auditing results below as a key success driver in this situation.
Step 3: Execute
Where the magic happens :). Jon “Natty” Natkins is developing a very robust how-to guide to walk through an example refactoring process from the ground up. To give a taste, we’ll show what the first few steps of the recipe described above look like in action, mapping from the original Stored Procedure approach to our new one using dbt.
Stored procedure approach (using SQL server code):
- Define a temp table selecting data from a raw table and insert some data into it
IF OBJECT_ID('tempdb..#temp_orders') IS NOT NULL DROP TABLE #temp_orders
SELECT messageid
,orderid
,sk_id
,client
FROM some_raw_table
WHERE . . .
INTO #temp_orders
- Run another INSERT from a second raw table
INSERT INTO #temp_orders(messageid,orderid,sk_id, client)
SELECT messageid
,orderid
FROM another_raw_table
WHERE . . .
INTO #temp_orders
- Run a DELETE on the temp table to get rid of test data that lives in production
DELETE tmp
FROM #temp_orders AS tmp
INNER JOIN
criteria_table cwo WITH (NOLOCK)
ON tmp.orderid = cwo.orderid
WHERE ISNULL(tmp.is_test_record,'false') = 'true'
We often see this process go on for quite some time (think: 1,000s of lines of code). To recap, the issues with this approach are:
- Tracing the data flow becomes REALLY hard because the code is a) really long and b) not documented automatically.
- The process is stateful - Our example #temp_orders table evolves throughout the process, which means we have to juggle several different factors if we want to adjust it.
- It’s not easy to test.
dbt approach
- Identify the raw source tables, and then map each of the INSERT statements above into separate dbt models, and include an automatically generated WHERE statement to eliminate the test records from the third step above.
— orders_staging_model_a.sql
{{
config(
materialized='view'
)
}}
with raw_data as (
select *
from {{ source('raw', 'some_raw_table')}}
where is_test_record = false
),
cleaned as (
select messageid,
orderid::int as orderid,
sk_id,
case when client_name in ['a', 'b', 'c'] then clientid else -1 end
from raw_data
)
select * from cleaned
- Write tests on the models to ensure our code is working at the proper grain
version: 2
models:
- name: stg_orders
columns:
- name: orderid
tests:
- unique
- not_null
- UNION the models together
{{
config(
materialized='table'
)
}}
with a as ( select * from {{ ref('stg_orders_a') }} ),
b as (select * from {{ ref('stg_orders_b') }} ),
unioned as (
select * from a
union all
select * from b
)
select * from unioned
We’ve just created a modular, documentable, and testable approach to manage the same transformations as an alternative.

Step 4: Audit your results
Any time you introduce a change to a technical process, it’s essential to check your results. Fortunately, dbt Labs maintains the audit helper package with exactly this use case in mind. The audit helper enables you to perform operations such as comparing row counts, and row by row validation on a table that’s updated by a legacy stored procedure to one that’s the result of a dbt pipeline in order to make sure the two are exactly the same (or, within a reasonable % deviation). This way, you have confidence that your new dbt pipeline is accomplishing the same goals of the transformation pipeline that existed before.
Summary
We’ve highlighted several of the pain points of working with stored procedures (mainly the lack of traceability and data testing) and how the dbt approach can help. Well documented, modular, testable code makes for happy engineers and happy business users alike 🤝. It also helps us save time and money by making pipelines more reliable and easy to update.
Over time, this approach is much more extensible than continuing to stack code on top of an unwieldy process. It’s also automatically documented, and using tests ensures the pipeline is resilient to changes over time. We continue mapping the data flow from the existing stored procedure to the dbt data pipeline, iterating until we achieve the same outputs as before.
We’d love to hear your feedback! You can find us on slack, github, or reach out to our sales team.
Appendix
dbt Labs has developed a number of related resources you can use to learn more about working in dbt, and comparing our approach to others in the Analytics ecosystem.