dbt + Machine Learning: What makes a great baton pass?


Special Thanks: Emilie Schario, Matt Winkler
dbt has done a great job of building an elegant, common interface between data engineers, analytics engineers, and any data-y role, by uniting our work on SQL. This unification of tools and workflows creates interoperability between what would normally be distinct teams within the data organization.
I like to call this interoperability a “baton pass.” Like in a relay race, there are clear handoff points & explicit ownership at all stages of the process. But there’s one baton pass that’s still relatively painful and undefined: the handoff between machine learning (ML) engineers and analytics engineers.
In my experience, the initial collaboration workflow between ML engineering & analytics engineering starts off strong but eventually becomes muddy during the maintenance phase. This eventually leads to projects becoming unusable and forgotten.
In this article, we’ll explore a real-life baton pass between ML engineering and analytics engineering and highlighting where things went wrong.
By doing so, we can hopefully solve this breakdown by answering questions like:
- Do we need a better Jupyter notebook?
- Should we increase the SQL surface area to build ML models?
- Should we leave that to non-SQL interfaces(Python/Scala/etc.)?
- Does this have to be an either/or future?
Whatever the interface evolves into, it must center people, create a low bar and high ceiling, and focus on outcomes and not the mystique of high learning curves.
TL;DR: There’s an ownership problem in the ML engineering & analytics engineering workflow. Luckily, the Modern Data Stack is making this baton pass smoother. This post will walk you through a recent project where I was able to see firsthand how these systems can work together to provide models that are built for long term accuracy and maintainability.
What does a baton pass look like today?
As an analytics engineer, I was paired with a ML engineer to determine when a customer will churn and what actions we could take to prevent it. We labored over a solution, the mechanics kind of worked, we presented to business stakeholders that wanted this, and 1 month later we were hopeful but skeptical. New data changes caused model drift, so the ML engineer logged a ticket for the data engineer/analytics engineer to fix…3 months later, no one remembered we did this. Does this sound familiar?
This happens because the “normal” way of doing things lacks long-term & explicit ownership. But how do these breakdowns happen?
Here’s what happened
After some initial planning, I knew we had this raw data living somewhere in our data warehouse. It was easy to make sense of this starting point for our work together. I wrote dbt transformations to massage this raw data and joined a couple tables together based on intuition of what variables mattered: daily active usage, number of users, amount paid, historical usage, etc.
The ML engineer stepped in from here. She was used to doing her statistics and preprocessing in python pandas and scikit-learn. Before she opened up her Jupyter notebook, we had a heart-to-heart conversation and realized the same work could be done through dbt. Preprocessing could be done through this open source dbt package and there were plenty of others like it in the package registry.
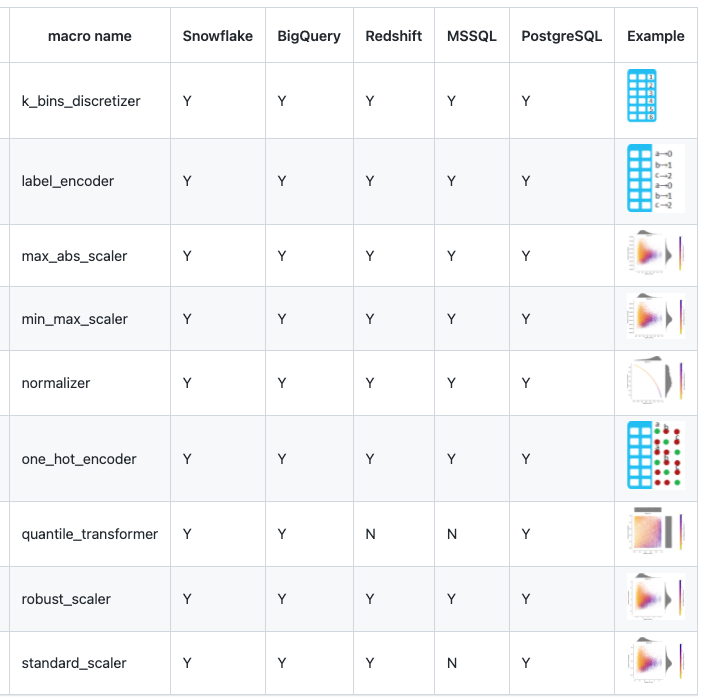
The ML engineer got the preprocessing steps (think: one-hot encoding, feature scaling, imputation) finalized. She used SQL to read the dbt models (tables) into a Jupyter notebook to perform model training. After iterating on the machine learning models and tracking model fit (think: AUC/Precision/Recall (for classification)), she ran the model over dbt-created tables and output the predicted results as a table in the database. To keep documentation clean, she configured a source within the dbt project to reflect this predicted results table. It wasn’t intuitive, but it was better than leaving it out of dbt docs.
Finally, she created a dashboard on top of this table to publicize model accuracy over time to end users. To schedule this, we went to the data engineer to string together the above in Airflow everyday at 8am and called it done.
Core Behaviors and Results (Where things went wrong)
Let’s parse out the job-to-be-done we’re seeing in our story.
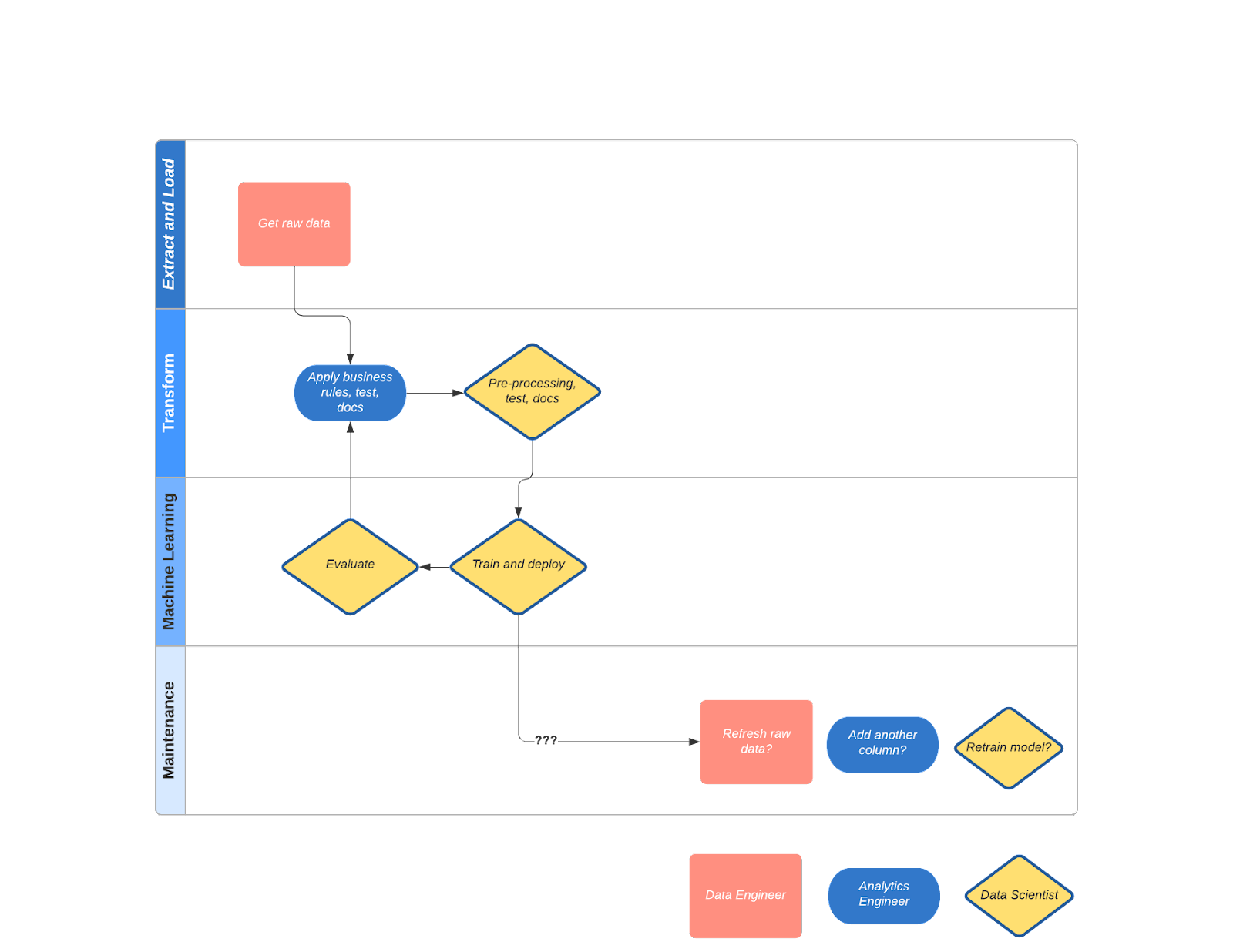
| Loading table... |
Our story starts with unity and a baton pass develops over time until we end with what looks more like playing hot potato. The building narrative is something I was proud of with my fellow ML engineer. The maintenance and validation of the machine learning output workflow is something we weren’t proud of. This happened because we were missing something critical: we weren’t united on who should do what in the long term (think: source data changes cascaded through the transformation->pre-processing->training steps->monitoring performance.) No wonder business users shrugged their shoulders at our results after 1 month because we assumed the other role would hold that baton pass forever.
Let’s make this simple:
- “Who makes data AND machine learning pipelines maintainable over time when data changes?”
If we get this question right, it makes answering this question easier: “How do we get people to use our work?”
How are tools evolving to heal the gap between analytics engineering & machine learning?
Let’s focus this question even more: What’s being done about the “maintenance over time” problem in our workflow? What would your team have done differently?
Build a better notebook experience that makes dbt and python more interoperable
Gluing together notebooks and dbt isn’t the most elegant experience today. It’d be nice to schedule notebooks in sync with my dbt jobs. All so I can better diagnose my problems in ML model drift.
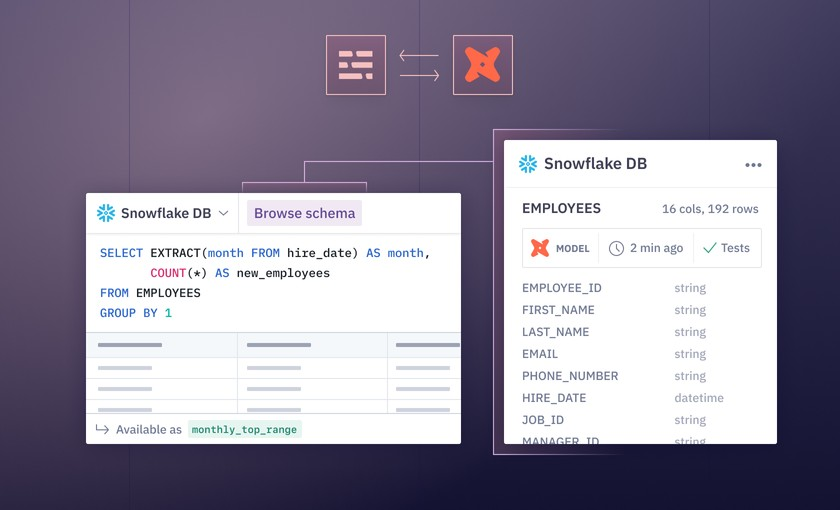
Hex
• Hex: Notebook experience with quality of life improvements. SQL query results can be read in as dataframes after running. dbt integration to verify data quality during development. Build parameterized data apps and give audiences one less context switch to a BI dashboard.
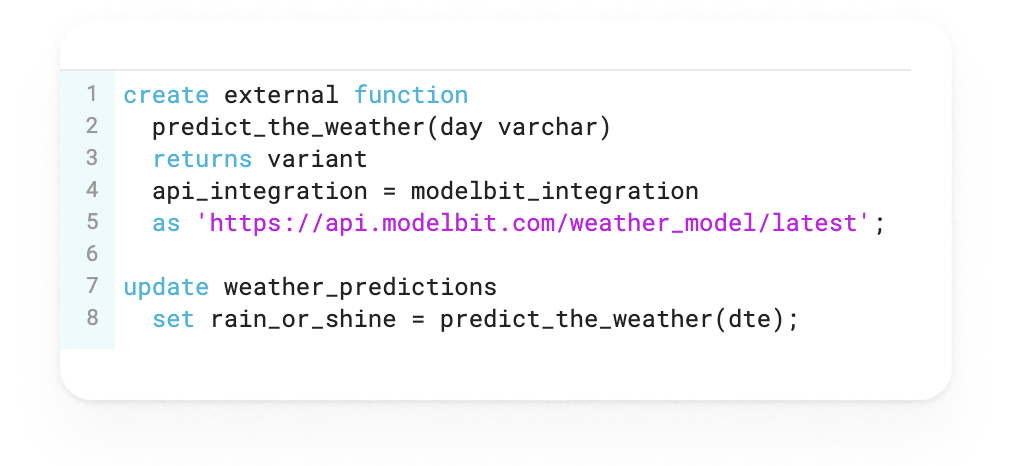
Modelbit
- Modelbit: Bring your own notebook with a huge quality of life improvement - enable dbt to call versioned ML models as external functions in SQL.
How would this change my story?
My ML engineer would know the quality of input data created by dbt before starting machine learning development. I could schedule this notebook in sync with my dbt jobs and know instantly if my ML model drift is caused by data quality vs. model logic. Also, I would create a data app (in Hex) where users plug in different input scenarios that feed into the predictive model. Even better, I could track versions of my ML models deployed over time in Modelbit + Hex and deploy ML external functions as dbt macros (by the way: how is this not more normal?!).
What are the tradeoffs?
I’d still have to export my predictive results back to the database and configure them as sources for dbt docs(depends if Modelbit is involved). People wouldn’t know at a glance the data lineage to power this notebook. But my gut tells me the tradeoff would be worth it because the ML engineer knows where to start problem solving even if the solution wasn’t readily available through SQL.
Bring machine learning to the SQL workflow
What if…SQL could do more than what we think it can or even should?
MindsDB
- MindsDB: Open source layer on top of a database using SQL syntax to create predictive models. Machine learning computation takes place in the MindsDB layer.
Continual
- Continual: Directly create a dbt model to predict your results. Evaluates ML models to use based on your dbt model configuration. Machine learning computation takes place in this layer and data warehouses where applicable (think: Snowpark API, Databricks).
Bigquery ML
- BigQuery ML: Use BigQuery-specific syntax to create machine learning models within the database and apply them as functions to your SQL to predict results. You get to import your own TensorFlow models!
Redshift ML
- Redshift ML: Use Redshift-specific syntax to create machine learning models within the database and apply them as functions to your SQL to predict results. You get to bring your own models too!
How would this change my story?
My ML engineer and I would get to unite on SQL even more. Wherever the pipeline broke in the (ELT-ML) process, SQL would be our entry-point together to figure out the problem. For simple machine learning problems (e.g., linear regression, classification), I would more easily understand and even own the full pipeline – with the advice and review of my ML engineer of course. And for Continual, I would elegantly add my machine learning model as an exposure (see below).
Beyond fixing problems once they arise, this workflow would avoid much of the complexity involved in building ML Ops pipelines: massive amounts of extra infrastructure (think: where does my python code run?). As a ML engineer, I want to live in a world where I can manage exploration, training, versioning, and inference from one control plane. In-warehouse ML has the potential to make that real.
What are the tradeoffs?
This wouldn’t solve for the ML engineer and her desire to inject custom ML models into this workflow without major effort (think: Jupyter notebooks if Continual isn’t her cup of tea). Also, if I wanted to build analyses on top of these predictions…I’d still have to configure them as sources in my dbt project (still a bit clunky). But my gut tells me the tradeoff would be worth it. Our shared SQL interface maintains ML models for months in a reality where fixing problems in SQL is easier than SQL, python, notebooks, BI dashboard (think: cognitive overload).
Make dbt integrate with multi-lingual support
It may be worth having python scripts live side by side dbt jobs and configurations. I can get better lineage and have one less tool to context switch to.
What are the tradeoffs of this tool path?
When things would go wrong, it’d still be a messy jumble to figure out how SQL changes inform python changes and vice versa. And I would need to care about which infrastructure my python code is running on. But my gut tells me the tradeoff would be worth it because there’d be less notebooks to schedule, and it’d be easier to align machine learning logic to dbt logic.
What outcomes matter?
This is the part of the story where you want me to declare a winner, but there isn’t one because I see a future where all of them can win.
What matters to me is what matters to you: “Which tradeoffs matter to get me enjoying working with my teammates and fixing problems more easily in my ELT-ML pipeline?”
My hope is that:
- When something goes wrong, it’s clearer where to start solving
- People are excited about baton passing work back and forth, less playing hot potato
- People have deep pride in a predictive analytics workflow that works
- Everyone gets to work on more interesting problems than clunkily fixing a machine learning pipeline across 5 browser tabs
- And most importantly, people use our collective gosh darn work to make real decisions
I’m less interested in the tools than understanding if this problem is one we can agree is painful enough to solve in the first place. Is this your story? Which future excites you? Which scares you?