dbt Core v2 is here: still open source, now rebuilt for what's next


Today, we published the first alpha release of dbt Core version 2.0, raising the baseline for what dbt users can expect from their transformation tool. As always, dbt Core's code is completely open source under the Apache 2.0 license. What makes this release significant is that dbt Core v2.0 is now built on the same foundations as the dbt Fusion engine – we've open-sourced a lot of Fusion code for the first time.
The launch of dbt Core v2.0 comes with key feature developments:
- Significant parse time improvements, especially on the largest dbt projects
- A tightly-defined language spec which makes it impossible to accidentally configure a
desciptininstead of adescription, and gives anyone integrating with the dbt ecosystem (including dbt's own development team!) a stable interface to build against. - New Parquet artifacts as a high-performance alternative to large JSON files that can be directly queried through DuckDB or your agent of choice
- A completely revamped local documentation experience, powered by those new artifacts and capable of scaling to projects of arbitrary size.
- A more streamlined way to build new adapters, powered by ADBC and the Arrow ecosystem
- A simplified installation process that removes the need to fight with Python's virtual environments
If you've been an early adopter of the dbt Fusion engine, these features might sound familiar. That's because the two-engine era is drawing to a close: from now on, dbt Core and Fusion will be built on a shared foundation. The subset of code (we're calling it the runtime) which we previously committed to releasing publicly under the ELv2 license is now under the Apache 2.0 license as dbt Core. Fusion will continue to extend that baseline by adding advanced capabilities - some are totally free to use, and other premium features are unlocked with a free login or payment method.
We think that this is the best way to continue to meet our commitments as stewards of the dbt framework, the best way to enable our One dbt vision, and the best way to maintain dbt's position as the standard for data transformation in the agentic era.
If you want to learn more about the new capabilities in dbt Core and where we're headed next, Jeremy, Elias, and I (Grace) just published another roadmap post - go check it out. For more detail about what is (and isn't) changing, and why we're doing this, read the rest of this post.
Putting all our efforts behind a single engine
When deciding how to release the dbt Fusion engine last year, we were faced with a set of strict requirements. Tristan described them in detail at the time, and you'll see them in the table below. The result was that we chose to build the new Fusion engine separately from Core, and under a different license (ELv2).
This worked well enough during Fusion's development period: new language features like Iceberg catalog support, --sample, and UDF definitions got equivalent OSS implementations in dbt Core v1.10 and v1.11.
But as Fusion's GA approaches, it's clear that its underlying technologies (like Rust, ADBC, and Parquet) are much better suited for future innovation. We want those technologies to be the foundation we can build on for everyone.
Revisit the same list of goals with one extra requirement – no bifurcated engine – and it comes out looking like this:
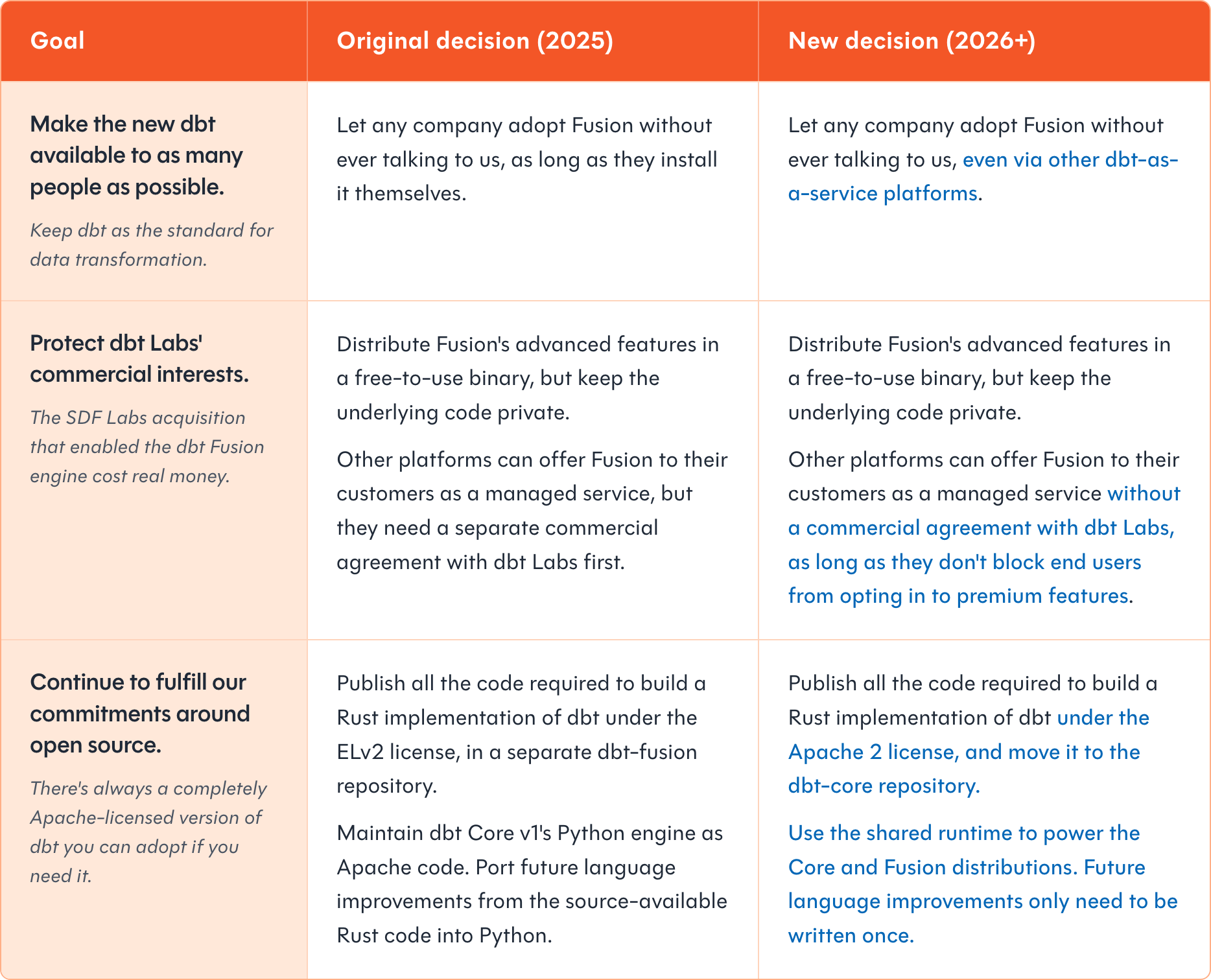
Better defining dbt Core's role in the ecosystem
As we introduced the different variants of the dbt Fusion engine last year, we explained that to distribute a Python program you have to distribute its underlying source code.
Historically, this has caused dbt Core to also be conflated with "the one you can use for free," or "the one you can use on your laptop," because the only way to provide a free, locally-installable version of dbt was for its Python code to be 100% open source. This meant the majority of dbt users missed out on useful capabilities whose implementation details we couldn't share.
By contrast, Rust projects can be distributed as binaries without disclosing any proprietary source code. This is why we're able to put out multiple free distributions of the v2 engine: one called Fusion providing the best experience in a binary containing some proprietary code, and another made up entirely of the Apache 2 open source code in the dbt-core repo.
Which v2 distribution should you choose for your use case? Almost certainly Fusion. Put another way: For the best free dbt CLI you can use locally and in production environments, install Fusion. It can do more than dbt Core out of the box and you can seamlessly enable other premium features over time if you choose to. Changes contributed to the dbt-core repository will be applied to Fusion. We also know that there is a small subset of teams who are required to use dbt Core today because of its license, or who are building custom things on top of the OSS code. If you find yourself in one of those camps (you'll know), we see you, and dbt Core v2.0 is here for you.
Regardless of the distribution you choose, it's still a single framework with a single language specification. Your critical business logic is portable in both directions.
Who benefits from these changes?
We think this is great for everyone in the dbt ecosystem, and a significant improvement over the status quo.
- We are open-sourcing a huge amount of IP, for anyone to use however they see fit.
- The enhanced Fusion binary is now available for use everywhere (including to power products competing with Fivetran + dbt Labs) with a more permissive license.
- Setting a clear roadmap encourages widespread adoption of v2 of the dbt framework, which in turn makes it easier for integrations to build against a common set of functionality.
- A shared runtime between the open source and proprietary distributions of dbt ensures that OSS users benefit directly from our ongoing investment in dbt, instead of trusting that features will be ported from Rust to Python on an ongoing basis.
Recap: what's changing, what's staying the same
 A high level visualization of the GitHub repositories as they were, and as they are now.
A high level visualization of the GitHub repositories as they were, and as they are now.What's new:
- We've open-sourced all the code required for a Rust implementation of v2.0 of the dbt framework. Some of the code was already in the dbt-fusion repository under the ELv2 license. Other parts hadn't made it across yet because we were still rapidly iterating. It's all now in the dbt-core repository, and it's all Apache 2.0 licensed.
- That code is the new dbt Core v2.0. Having the high-performance Rust implementation of dbt as the baseline for all users reduces complexity and makes it easier to keep moving the dbt framework forward. It's in alpha today, and we want your help to make sure it works for everyone as it moves towards GA. Give it a try!
- The enhanced, precompiled Fusion binary can now be provided as a managed service by others. We have relicensed the Fusion binary to be more permissive than ELv2. As before, some features will only work if you've authenticated, either with a free login or a paid dbt platform account. Companies offering Fusion as a managed service must allow end users to enable these premium features.
What's not changing:
- The existing Python code is still available. We just released a new beta version of dbt Core v1.12.0, and all the old versions are still available on PyPI and GitHub. You don't have to move to v2.x today, tomorrow, or ever. But just like the move from v0 to v1.x back in 2021, over time there will be capabilities that you'll need to upgrade to access.
- You can still use the enhanced, precompiled Fusion binary completely for free. We think this is the best way to use dbt. It contains more capabilities – including a built-in high-performance SQL linter – than you would get from building the Apache codebase yourself, even if you never create a dbt account.
- Building dbt remains a team sport. You can continue to submit issues and PRs to the dbt-core repository, as some 300 community members did on the (now archived) dbt-fusion repository during its preview/beta periods, and as ~1200 others have done on the dbt-core repository during its version 1.x era.
What's next?
Whichever distribution of v2.0 you're upgrading to, it's a major version change and those come with some bumps where we break from the past to get ready for the future. Based on dbt's adoption curve over the last five years, most people reading this weren't part of the migration from dbt v0 to v1.0, so this could be your first time.
It's easier this time: the dbt-autofix package and our agent skill for version upgrades mean you can get a long way very quickly. The best way to prepare to migrate is to first upgrade to dbt v1.12 (or the "Latest" release track in the dbt platform).
It enforces many of the behavior changes that are fully removed in v2.0 of the framework, and even ships with the Fusion-powered project parser so that you can check whether your project will parse correctly. Run dbt parse --use-v2-parser to try it out. If your project succeeds, you're good to go, and should check out the installation guide to switch over.
If you have further questions, leaders from the newly-combined Fivetran + dbt Labs executive team will be holding a fireside chat on June 25th, 2026. Register for the session here, hosted by Tristan Handy (Co-founder and President) and Taylor Brown (Co-founder and COO).